Table of Contents
- Why Integrations Fail After Seemingly Successful Launches
- Observability That Reflects Business Reality
- 30-60-90 Day Implementation Plan
- Common Failure Patterns and Fixes
- FAQ
Warehouse systems and customer-facing websites now operate as one commercial surface. If stock values are stale, customers buy unavailable products. If shipment states lag, support volume spikes. If order transitions fail silently, revenue leakage starts immediately.
The core challenge is not connecting two systems once. The challenge is sustaining accurate synchronization under real conditions: retries, partial failures, traffic spikes, schema changes, and cross-team coordination pressure.
Teams that perform well treat this as an operating system, not an API task. They define clear ownership, build for replay safety, monitor business events, and prepare communication patterns before incidents happen.
Unicorn Platform helps by making customer-facing communication updates fast during both normal operations and degraded states. That speed is valuable only when the integration layer underneath is predictable.
sbb-itb-bf47c9b
Quick Takeaways
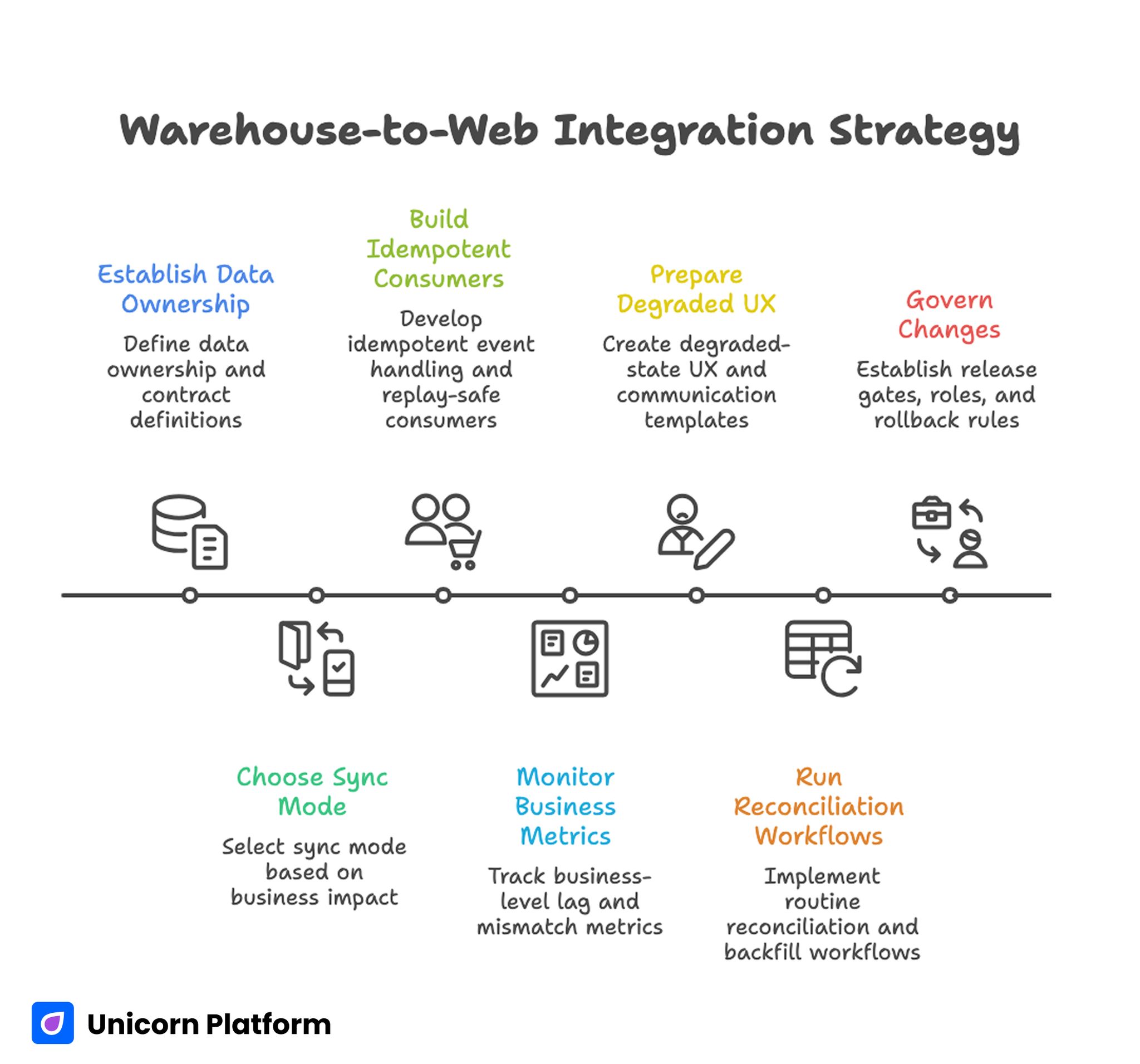
Warehouse-to-Web Integration Strategy
- Start with data ownership and contract definitions before writing transport code.
- Choose sync mode by business impact, not by technical preference.
- Build idempotent event handling and replay-safe consumers from day one.
- Monitor business-level lag and mismatch metrics, not only server uptime.
- Prepare degraded-state UX and external communication templates in advance.
- Run reconciliation and backfill workflows as routine operations.
- Govern changes with explicit release gates, roles, and rollback rules.
Why Integrations Fail After Seemingly Successful Launches
Many implementations look stable in early testing and fail under production variability. The reason is usually hidden coupling between assumptions that were never formalized.
Common patterns include ambiguous source-of-truth definitions, inconsistent enum handling across systems, and retry logic that replays business transitions without protection. Each issue looks small in isolation, but together they create cascading data drift.
The fastest route to stability is to formalize operational assumptions first, then code against those assumptions with clear validation and observability.
Source-of-Truth Matrix Before Any API Work
Every critical field should have one authoritative owner. Inventory quantity, reserved stock, order payment state, shipment milestones, cancellation reason, and refund status all need explicit ownership.
Without ownership clarity, teams "fix" inconsistencies by writing data in multiple places, which creates circular drift and hard-to-debug reconciliation problems.
A simple source-of-truth matrix prevents this. For each field, define owner system, update trigger, allowed overwrite paths, and conflict resolution behavior.
Contract-First Integration Design
Transport code should follow contract design, not the reverse. Contracts should define field types, precision, time semantics, enum vocabularies, null behavior, and error responses with concrete examples.
Human-readable contract docs matter as much as machine-readable schemas. Support, operations, and analytics teams rely on these rules when diagnosing customer-facing inconsistencies.
Contract versioning should be planned from the first release. Additive changes, deprecations, and breaking transitions each require distinct rollout paths and compatibility windows.
Choosing Sync Mode by Business Criticality
Not every workflow needs immediate propagation. Real-time sync adds complexity, and complexity increases failure surface area.
Use near-real-time for inventory availability and order-status transitions that directly affect purchase decisions. Use batch for reporting aggregates and lower-risk metadata where latency tolerance is higher.
This classification should be explicit and reviewed quarterly. As business models evolve, acceptable latency often changes.
Event Model and Replay Safety
Distributed systems retry. If handlers are not idempotent, retries become data corruption. Duplicate shipping notifications, repeated status transitions, and double inventory reservations are common symptoms.
Idempotency keys should be first-class entities in event processing. Consumers need dedupe logic plus safe state-transition guards that reject invalid transition repeats.
Replay tooling should also be constrained. Reprocessing historical events can restore consistency, but only if consumers are explicitly designed for replay-safe behavior.
Order Lifecycle Mapping Across Systems
Order state models often differ between platforms. One system may represent fulfillment as a linear state, while another models parallel sub-states by line item or warehouse location.
A reliable implementation maps every lifecycle transition with preconditions and postconditions. Include partial shipment behavior, split fulfillment, cancellation windows, and refund branching.
Lifecycle mapping should be validated with business scenarios, not only technical tests. Real customer flows expose edge cases that synthetic test payloads miss.
Inventory Integrity and Reservation Logic
Inventory errors are among the most visible trust failures in commerce. Overselling and phantom stock usually originate in reservation rules, not in display templates.
Teams should separate available, reserved, and committed quantities clearly. Reservation expiration rules, concurrency handling, and compensation actions after payment failure must be explicit.
Where catalog complexity is high, maintaining clear website communication becomes equally important. The structure in the simplest way to create your software company page is useful for turning technical reliability choices into buyer-facing trust language.
Validation Layers That Stop Bad Data Early
Validation should occur at ingress, transformation, and egress stages. Ingress validation checks schema conformity. Transformation validation checks business logic consistency. Egress validation checks payload safety before downstream publication.
Reject invalid payloads fast with actionable error context. Silent acceptance of malformed events is usually more damaging than explicit failure.
Validation rules should be versioned and tested as code. Manual rule drift is a frequent source of inconsistent behavior across services.
Error Handling, Queues, and Dead-Letter Strategy
Queue-backed designs need explicit failure paths. If poison messages are retried indefinitely, backlog grows and delays spread to healthy events.
Dead-letter queues should include clear triage ownership, replay policy, and severity classification based on business impact. Not every failed message deserves immediate escalation, but critical transitions do.
Operational dashboards should show queue age, retry rates, and dead-letter growth by event type so teams can prioritize with context.
Observability That Reflects Business Reality
Infrastructure metrics alone are insufficient. Integration health needs business-aware signals: inventory mismatch rate, order transition lag, shipment event delay, and customer-impacting error frequency.
Service-level objectives should include user-facing thresholds, not only system availability percentages. A system can be technically "up" while still failing key commercial workflows.
Alerting should be tiered. Immediate paging for checkout-impacting failures, scheduled review alerts for low-severity drift, and trend alerts for rising latent risk.
Outage Response and Graceful Degradation
No production system is outage-proof. Resilience depends on how quickly teams detect disruption, reduce impact, and communicate clearly.
Graceful degradation patterns should be prepared in advance. Examples include "availability verification in progress" states, delayed update banners, and conservative fallback estimates instead of stale certainty.
In page operations, response speed improves when communication modules are easy to publish. The delivery workflow in build your custom website without coding is useful for maintaining rapid, controlled updates during incidents.
External Communication Framework During Incidents
Communication quality determines trust trajectory during disruption. Customers can tolerate temporary delays when status is clear, timelines are realistic, and updates are consistent.
Define message formats by audience. Support teams need customer-safe summaries, engineering teams need technical incident detail, and leadership teams need decision-level impact snapshots.
Pre-approved language templates reduce delay and prevent contradictory messages across channels.
Security and Access Governance
Integration reliability is inseparable from security posture. Service accounts should follow least-privilege scope. Secrets should rotate on schedule. Requests should be signed where appropriate. Audit trails should be queryable.
Access boundaries need review cadence. Temporary permissions granted during incidents often persist unless explicit expiry controls are enforced.
Security checks should be part of integration release gates, not a separate afterthought owned by another team.
Testing Strategy Beyond Unit Coverage
Unit tests validate local logic, but integration resilience needs broader coverage: contract tests, consumer-driven compatibility checks, failure-mode simulations, and replay tests with real-like traffic patterns.
Staging environments should include controlled chaos scenarios: delayed acknowledgments, queue spikes, timeout bursts, and partial downstream unavailability.
Business-scenario tests are essential. If test suites do not include realistic customer journeys, teams miss high-impact defects until production.
Reconciliation and Backfill Operations
Even resilient pipelines drift over time. Reconciliation jobs compare system-of-record data against website state and flag mismatches before customers report them.
Backfill operations should be deterministic and audited. Teams need to know exactly what changed, when it changed, and why it changed.
A healthy program runs reconciliation routinely, not only after major incidents. Routine checks convert emergency work into predictable operations.
Peak Event Preparedness
Promotions and seasonal peaks amplify every weak assumption. Throughput, queue depth, and dependency latency can change rapidly under campaign-driven load.
Peak preparation should include traffic simulations, prioritization rules for critical events, and safe-mode behavior for non-critical updates.
Customer expectation management during peaks is part of reliability. Clear fulfillment and status messaging reduces support pressure and preserves trust when latency temporarily increases.
Dependency and Vendor Risk Management
Many failures originate in upstream or downstream dependencies. Queue providers, carrier APIs, payment services, and analytics relays can all introduce instability.
Maintain a dependency register with owner, SLA, failure mode, and fallback behavior. Review the register quarterly and after major incidents.
Fallback paths should be tested, not hypothetical. Documented contingencies that were never exercised frequently fail when needed most.
Team Operating Model and Ownership
Stability improves when ownership is explicit. Assign one owner for contracts, one for runtime health, one for reconciliation quality, and one for external communication readiness.
Cross-functional reviews should be short and decision-focused. Weekly reviews address tactical anomalies. Monthly reviews address structural adjustments.
Ownership clarity also improves onboarding. New team members understand where to escalate and how to contribute without creating policy drift.
KPI Framework Tied to Commercial Outcomes
Technical KPIs should map to business impact. Useful examples include inventory accuracy, order-state latency, retry recovery success, incident MTTR, cancellation rate drift, and support ticket surge during degraded periods.
KPI reviews should ask one core question: which integration improvements reduce customer friction and protect revenue most effectively.
This framing prevents optimization theater where teams improve low-impact metrics while high-impact risk remains unchanged.
30-60-90 Day Implementation Plan
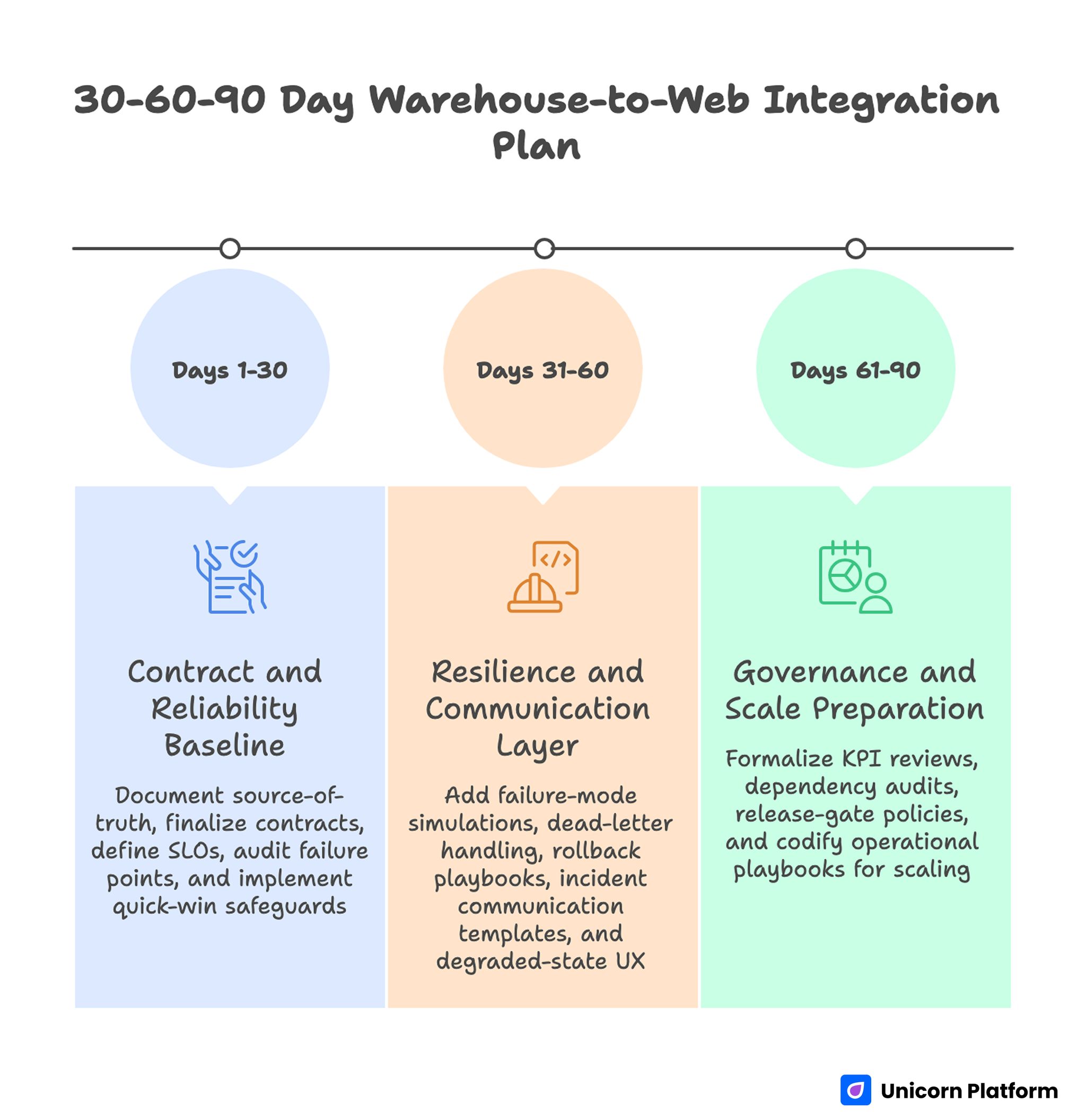
30-60-90 Day Warehouse-to-Web Integration Plan
Days 1-30: Contract and Reliability Baseline
Document source-of-truth matrix, finalize contract versions, and define critical SLOs. Audit current failure points in event handling, validation, and reconciliation.
Implement quick-win safeguards: idempotency checks, queue triage ownership, and basic lag alerts for high-risk events.
Days 31-60: Resilience and Communication Layer
Add failure-mode simulations, dead-letter handling automation, and tested rollback playbooks. Build incident communication templates with audience-specific variants.
Deploy degraded-state UX blocks and validate behavior under controlled disruption drills.
Days 61-90: Governance and Scale Preparation
Formalize monthly KPI reviews, quarterly dependency audits, and release-gate policies for integration changes.
Codify operational playbooks with explicit ownership and escalation thresholds so the model scales with transaction volume.
Common Failure Patterns and Fixes
Failure: Endpoint-First Development
Teams implement API calls before defining shared contracts. Fix this by enforcing contract approval before production wiring.
Failure: Retry Logic Without Idempotency
Duplicate events mutate state repeatedly. Fix this with idempotency keys and transition guards.
Failure: Infrastructure-Only Monitoring
Incidents are detected late because business drift is invisible. Fix this with event-level lag and mismatch dashboards.
Failure: Communication Built During Crisis
Updates are inconsistent and delayed. Fix this with preapproved templates and defined audience channels.
Failure: Reconciliation as Emergency Work
Data drift accumulates between incidents. Fix this with scheduled reconciliation and audited backfill routines.
Failure: Ownership Ambiguity
Teams debate responsibility during outages. Fix this with explicit runbook ownership and escalation paths.
Financial Risk Modeling for Reliability Priorities
Reliability programs become easier to fund when teams quantify commercial risk in practical terms. Instead of discussing incidents only as technical failures, estimate cost exposure by failure type: oversell refunds, cancelled orders, support escalation load, and reputation loss from fulfillment uncertainty.
A simple model can assign expected hourly impact to major failure classes. Checkout-impacting inventory errors, delayed shipment-state transitions, and status-notification failures usually carry very different business costs. Prioritizing by estimated exposure helps teams allocate effort where recovery speed and prevention return are highest.
Risk modeling should also include secondary effects. Delayed updates can increase support contacts, which slows response quality in unrelated channels and compounds customer frustration. Capturing these knock-on effects improves prioritization decisions during quarterly planning.
When financial estimates are reviewed alongside technical metrics, leadership conversations become more concrete. Teams can justify resilience work as revenue protection and customer-experience defense, not as abstract infrastructure investment.
Reliability Maturity Review Cadence
Monthly dashboard checks are useful, but maturity improves faster with structured quarterly reviews. A quarterly review should evaluate contract health, observability quality, reconciliation coverage, incident communication performance, and dependency risk posture in one session.
Each review should produce specific upgrades rather than broad conclusions. Examples include tightening schema change policy, reducing alert noise through threshold tuning, improving dead-letter triage ownership, or expanding degraded-state UX coverage for high-value routes.
A practical maturity scorecard can use five dimensions:
- contract clarity and version discipline
- event-processing resilience and replay safety
- detection speed and business-impact visibility
- recovery discipline and communication quality
- governance consistency across teams
Scoring trends across these dimensions gives teams a clearer signal than isolated incident anecdotes. If maturity scores stall for two quarters, operating model changes are usually needed, not only tactical fixes.
FAQ: Warehouse-to-Web Integration
1) Should all inventory updates be real-time?
No. Real-time should be reserved for high-impact decisions. Many secondary flows can run safely on near-real-time or batch schedules.
2) What is the fastest way to reduce integration risk?
Define field ownership and idempotency behavior first. Those two decisions prevent a large share of high-impact drift.
3) How often should reconciliation run?
Frequency should reflect business risk. High-velocity fields need more frequent checks than low-impact metadata.
4) What metric best signals customer-facing reliability?
Order-state and inventory mismatch lag is usually a strong early indicator because customers feel it quickly.
5) How do we prioritize incidents during peak traffic?
Use business impact tiers: checkout blockers first, fulfillment misstates second, non-critical reporting delays later.
6) When should teams rebuild architecture?
Re-architecture is justified when current topology cannot meet required SLOs without repeated manual intervention.
7) Do we need separate communication for each audience?
Yes. Technical, support, and leadership audiences need different detail levels while staying aligned on core facts.
8) What makes runbooks effective?
Tested procedures with clear owners, escalation triggers, and rollback criteria. Untested runbooks rarely hold under pressure.
9) Can AI help with integration reliability?
It can help with anomaly detection and incident summarization, but core correctness still depends on contract quality and deterministic processing.
10) How do we prove reliability improvements are worth the effort?
Tie reliability changes to reductions in cancellations, support load, and recovery time. Commercial impact validates technical investment.
Teams should also compare pre- and post-change customer behavior in affected workflows. If availability accuracy improves and ticket escalation drops in the same period, reliability improvements are creating measurable trust value. This comparison becomes stronger when you track the same segments over multiple cycles instead of relying on one short interval.
Another practical control is a short post-incident readiness check within seven days of recovery. This check verifies that alert thresholds, fallback messages, and escalation paths were actually updated from the lessons learned.
Teams that close incidents without this short follow-up often repeat the same coordination mistakes. A lightweight verification step keeps operational learning alive and prevents resilience work from degrading into documentation theater.
Final Takeaway
Warehouse-to-web integration quality determines whether commerce operations scale cleanly or fail under routine variability. The durable advantage comes from explicit contracts, replay-safe processing, business-level observability, and prepared communication discipline.
With structured governance and fast publishing support in Unicorn Platform, teams can turn integration reliability from a reactive firefighting task into a repeatable growth capability.
The compounding benefit appears when accuracy, communication, and recovery discipline improve together across multiple quarters instead of as isolated fixes after individual incidents.
Related Blog Posts
- HIPAA-Compliant Website Builders in 2026: A Practical Selection and Implementation Guide
- Ecommerce CRO in 2026: A Practical System to Recover Lost Revenue
- Digital Accessibility Operations in 2026: A Startup Playbook for Inclusive Growth and Trust
- Niche Marketplace Strategy in 2026: How to Move From Idea to Reliable Two-Sided Traction
