Table of Contents
- Why No-Cost Builders Still Win in Early-Stage Execution
- Copy System for High-Quality Leads
- 30-Day Execution Rhythm
- Implementation Toolkit for the Next 60 Days
- Common Mistakes and Fixes
- FAQ
Early-stage teams often lose momentum before they lose money. They delay launches, over-research tools, and wait for polished design assets while real users still have not seen the offer.
No-cost builder workflows help solve that exact problem. They reduce setup friction, shorten the path to real feedback, and let teams focus on conversion logic instead of technical overhead.
The downside appears when speed is used without structure. Fast publishing with weak page hierarchy creates noisy analytics, low-quality leads, and unnecessary redesign cycles.
This guide shows how to prevent that failure mode. It gives a full operating system for launch, optimization, team handoff, and upgrade timing so a free setup can produce serious outcomes.
sbb-itb-bf47c9b
Quick Takeaways
Unveiling the Dimensions of Launch Success
- Launch quality depends more on decision structure than on template aesthetics.
- One page with one objective usually outperforms broad multi-goal launches.
- Trust should appear near action points, not buried in low-attention zones.
- Channel-specific opening variants improve conversion quality without heavy rebuilds.
- Upgrade decisions should follow measured constraints, not perceived status pressure.
Why No-Cost Builders Still Win in Early-Stage Execution
The strongest argument for no-cost tools is not budget relief. The stronger argument is learning velocity under uncertainty.
When teams can publish and iterate quickly, they discover message fit faster. That speed compounds because each weekly change produces cleaner insights for the next cycle.
A no-cost setup also lowers organizational friction. Founders, marketers, and operators can collaborate around one live page instead of waiting on slow build queues.
Execution discipline is still mandatory. Teams that skip structure usually blame the tool for outcomes caused by unclear offers and weak conversion flow.
For teams that want a practical baseline launch path, this guide on building a new site quickly with zero upfront spend gives a useful starting framework. It is most valuable when paired with weekly review discipline after initial publication.
The Three-Phase Operating Model
A reliable website growth process on a no-cost stack has three phases. Each phase has a different objective and different success criteria.
Phase one is launch clarity. The goal is one coherent page with one primary action path and working analytics.
Phase two is conversion refinement. The goal is to reduce friction and improve qualified action completion through controlled tests.
Phase three is scale decisioning. The goal is to decide whether current limits are still acceptable or whether growth requires upgraded capabilities.
Teams that mix these phases often stall. Keeping phases distinct improves priorities and keeps meetings focused on the right decisions.
Builder Selection Criteria That Matter in Real Workflows
Most comparison pages prioritize visual freedom and ignore production constraints. Real performance depends on whether teams can ship consistent updates under weekly pressure.
Use five decision criteria with weighted scoring. Weighted scoring keeps comparisons objective when multiple stakeholders have different preferences.
- Editing speed for non-technical contributors.
- CTA and form flexibility for conversion experiments.
- Baseline SEO controls and structural clarity.
- Collaboration flow across content, growth, and QA roles.
- Migration safety if scale eventually requires upgrades.
A structured shortlist review avoids endless comparison loops. Once two or three options pass your baseline score, move to live testing rather than further speculation.
When evaluating shortlists, this walkthrough on creating online pages quickly with practical constraints is useful for reality-checking priorities. It helps teams prioritize execution reliability over feature hype.
Launch Objective Design
Pages fail most often when they try to do everything at once. Users cannot follow mixed intent, and teams cannot interpret mixed metrics.
Pick one primary outcome for version one. Examples include waitlist signup, booking request, lead form completion, or newsletter subscription.
Every major section should support that outcome directly or indirectly. Secondary actions may exist, but they should never compete with the primary CTA hierarchy.
This single decision usually improves conversion quality before any design or copy rewrite happens. Clear primary intent reduces ambiguity across every downstream section.
Offer Clarity Framework
Offer clarity has four required parts: audience, problem, mechanism, and expected result. If one part is missing, visitors guess, and guessing reduces conversion confidence.
Audience clarity should be explicit enough for self-qualification. Problem clarity should map to real urgency, not generic dissatisfaction.
Mechanism clarity should explain how the outcome is produced. Expected result should remain realistic and context-sensitive rather than absolute.
The framework works because it helps users decide quickly whether the page is relevant. Faster qualification improves both conversion volume and lead quality.
First-Screen Architecture
The first screen should answer three questions in seconds. Visitors need to know whether the page is for them, what outcome they can expect, and what step comes next.
Headline language should combine audience and practical result. Supporting copy should add one mechanism cue so the claim feels believable.
Button copy should match readiness level. High-commitment language in cold contexts usually hurts completion.
Avoid clutter in this zone. Multiple equal-priority actions, dense badge stacks, and abstract promises reduce scan speed and increase bounce probability. UX research from Nielsen Norman Group shows that users typically scan web pages in an F-shaped pattern, meaning that hierarchy, spacing, and first-screen clarity strongly influence what users notice and how quickly they make decisions.
For teams refining this section with startup traffic, the reference on simple startup landing creation patterns helps keep first-screen logic practical. It is particularly useful when campaigns must launch under tight timelines.
Section-by-Section Conversion Map
Section-by-Section Conversion Map
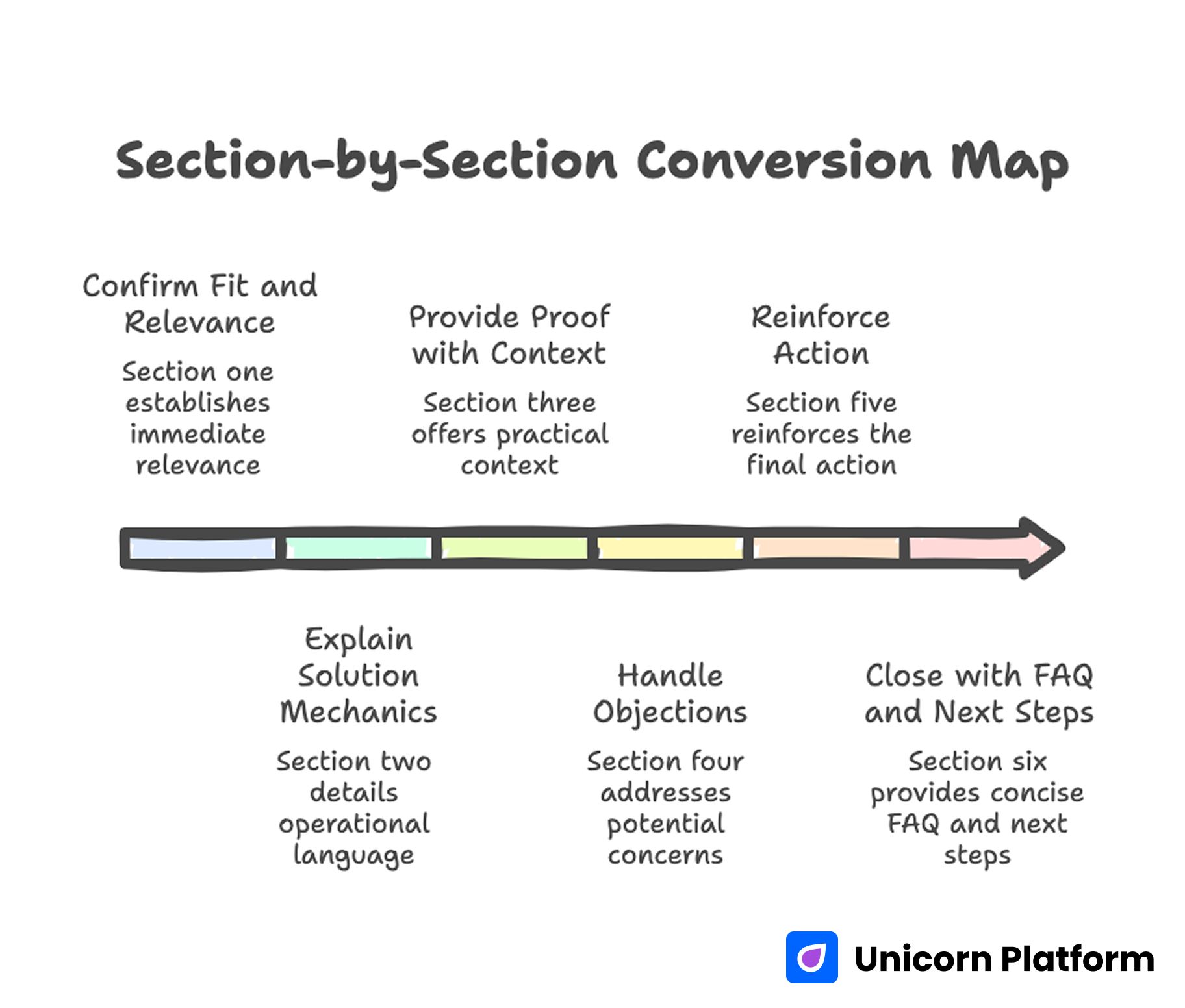
A strong page uses section order that mirrors user decision order. Each block should reduce a specific uncertainty.
Section one confirms fit and immediate relevance. Section two explains solution mechanics in operational language.
Section three provides proof with practical context. Section four handles objections before the final action reinforcement.
Section five closes with concise FAQ and clear next steps. This map works across many verticals because it aligns reading flow with decision flow.
Teams should keep this map stable while testing one variable at a time. Stable architecture improves interpretability across iterations.
Copy System for High-Quality Leads
Copy quality is measured by decision usefulness, not by brand tone preferences. Strong copy helps the right people act and the wrong people self-filter.
Use precise nouns and measurable language. Replace broad terms like "better growth" with concrete outcomes tied to timeframe or workflow.
Add scope boundaries early. A short "best fit / not fit" block often improves lead quality by reducing mismatched submissions.
Keep sentence rhythm clear and direct. Dense, metaphor-heavy language may sound polished but often reduces conversion clarity.
Practical Copy Checklist
- Audience fit is explicit.
- Core problem is concrete.
- Mechanism is understandable.
- Claims have nearby proof.
- CTA language matches commitment level.
This checklist catches most high-impact copy errors before launch. It also improves consistency when multiple contributors edit the same page.
Proof Strategy That Builds Confidence
Generic praise no longer moves decisions in most categories. Visitors need proof that connects outcome claims to realistic conditions.
Use context-rich proof units. Each unit should include use case, implementation context, and observed result.
Place proof where hesitation peaks. Proof near form areas and commitment zones is usually more effective than proof only at the page bottom.
Mix social proof with process proof. Testimonials show outcomes, while process proof shows why outcomes are repeatable.
For teams creating first proof systems quickly, the guide on building with simple free workflows provides practical ideas for proof placement. Strong placement decisions often outperform adding more proof volume.
Objection Handling System
Objection handling should be designed, not improvised. Most drop-offs happen when one unresolved concern blocks action.
Common concern classes include fit uncertainty, pricing ambiguity, implementation effort, and trust risk. Each class deserves a concise response in conversion-critical sections.
A strong response format is "clarification plus confidence cue." Clarification explains facts, and confidence cue explains why users can rely on those facts. This structure keeps objection responses short while still persuasive.
Place objection responses before final CTA reinforcement. This lets users move directly from uncertainty resolution into action.
FAQ Design for Decision Support
FAQ sections should be built from real questions, not from placeholder assumptions. Sales calls, support logs, and form comments are the best sources.
Each answer should remove one practical blocker with minimal verbosity. Long theoretical answers reduce scan speed and weaken utility.
FAQ can also support topical relevance for search, but user clarity must remain the primary objective. Keyword repetition without decision value hurts both trust and performance.
Refresh FAQ monthly. As your offer and audience evolve, stale answers quietly reduce conversion quality.
Mobile-First Execution Rules
Many early-stage teams still design desktop first and patch mobile later. That sequence usually fails because high-intent discovery often happens on phones.
Mobile flow should prioritize readable hierarchy, concise sections, and thumb-friendly controls. Visual complexity that looks premium on desktop can become friction on small screens.
Form interactions should be progressive and clear. Short field sequences with explicit error states reduce completion drop-off.
Real-device testing is essential. Emulators miss interaction details that affect live conversion behavior.
Mobile QA Checklist
- Headline wraps cleanly.
- Primary CTA is visible without confusion.
- Form fields are tap-friendly.
- Error states are understandable.
- Scroll flow preserves context.
This quick checklist prevents many avoidable losses. It is easy to run and fits well into fast publishing workflows.
Performance Standards for No-Cost Stacks
Page speed is both a technical metric and a trust signal. Slow loading can destroy confidence before users evaluate offer quality.
Set a practical baseline for every major update. Keep media lightweight, avoid unnecessary script load, and validate first paint behavior after edits.
Focus on consistency, not perfection. Stable performance under normal conditions matters more than occasional peak results in lab tests. According to Google’s official Web Vitals documentation, Core Web Vitals measure real-world user experience signals including loading speed, interactivity, and visual stability, and are used as part of broader page experience evaluation.
Track conversion changes after major media or layout updates. Performance regressions often look like message problems until measured directly.
Search Visibility Strategy Without Enterprise Tooling
No-cost stacks can still support useful search growth when architecture and content are intentional. Ranking fundamentals remain similar across plan tiers.
Build one primary conversion page and add a small set of supporting pages that answer high-intent buyer questions. This creates topical depth and user navigation value.
Use clean headings, descriptive titles, and clear section semantics. Avoid copy duplication across pages with minor keyword swaps.
Internal links should guide users to deeper context where needed. Link placement should follow user decisions, not arbitrary content quotas.
Search growth is usually slower than paid traffic, but high-quality organic visits often convert with stronger long-term efficiency. That efficiency becomes more visible after several monthly iteration cycles.
Channel-Specific Messaging Framework
One static hero rarely works across all acquisition channels. Search, social, referral, and community traffic arrive with different intent levels.
Keep one shared page backbone and vary only the opening block by source. This approach improves relevance while preserving test interpretability.
Search-oriented variants should lead with problem-to-outcome clarity. Social variants should add trust and context earlier because intent is often less defined.
Referral variants should reinforce credibility and next-step simplicity since trust is partially transferred from the source. Clear proof language helps protect that transferred trust from dilution.
This model keeps production light while improving qualified conversion behavior. It lets teams scale experimentation without creating major content debt.
Analytics Model for Weekly Decisions
Analytics should answer operational questions. Dashboards without decision context create activity without progress.
Use one primary metric and one guardrail per cycle. Primary metrics track intended lift, while guardrails protect quality.
A practical baseline set includes qualified sessions, CTA clicks, completion rate, and a downstream quality indicator such as lead relevance or activation depth. This combination balances volume signals with quality protection.
Review data by source, not only in aggregate. Aggregate improvement can hide channel-level degradation that hurts real growth quality.
Document each cycle with hypothesis, change summary, and observed result. This history speeds future decisions.
Experiment Discipline for Small Teams
Small teams often make many edits at once and lose interpretability. Controlled experimentation is the fastest way to improve under resource constraints.
Change one major variable per cycle when possible. Keep architecture stable so outcome shifts can be attributed with confidence.
Prioritize tests by bottleneck severity, not by ease of implementation. High-impact friction points deserve first attention.
End each cycle with a clear decision: keep, revert, or iterate. Ambiguous endings create backlog noise and reduce team confidence.
Example Test Priorities
- First-screen clarity versus bounce.
- Form friction versus completion.
- Proof placement versus qualified conversion.
- Objection section depth versus abandonment.
These priorities usually outperform low-impact cosmetic tests. They also create clearer causal signals in weekly review meetings.
Team Roles and Handoff Protocol
Speed without ownership causes quality drift. Clear role boundaries keep updates coherent across multiple contributors.
Assign at least four responsibilities: message owner, proof owner, analytics owner, and final QA owner. One person can hold multiple roles, but the responsibilities must be explicit.
Use short pre-publish checks with fixed criteria. Long unstructured review sessions often produce subjective feedback without actionable decisions.
Record publish date, scope of changes, and expected metric movement. This makes later analysis faster and more reliable.
Reliable handoff process is a competitive advantage for small teams because it multiplies output quality without increasing headcount. Handoff discipline also reduces regression risk when ownership shifts.
30-Day Execution Rhythm
30-Day Execution Rhythm for Continuous Improvement
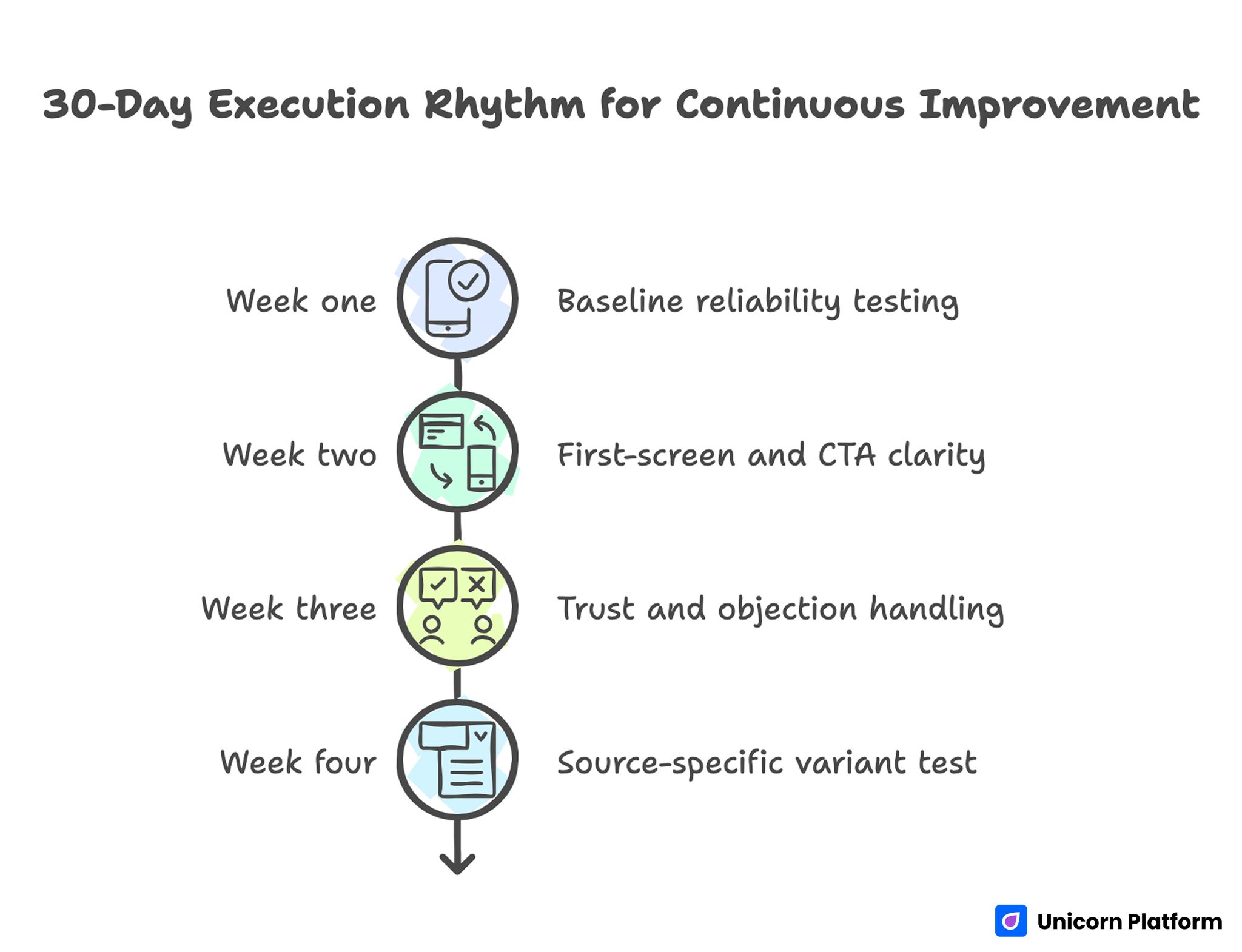
A monthly cycle gives enough time for meaningful tests while keeping momentum high. It balances speed with sufficient data accumulation for useful decisions.
Week one should focus on baseline reliability, including tracking integrity and mobile QA. Weak technical reliability can invalidate all later experiments.
Week two should prioritize first-screen and CTA clarity. Early-stage lift usually comes from better relevance and action alignment.
Week three should improve trust and objection handling using real feedback from users and support channels. These edits often raise completion quality.
Week four should run one source-specific variant test and produce a documented keep-or-iterate decision. Closing each cycle with a decision prevents test backlogs from accumulating.
Repeat the cycle with one central learning objective each month. A single objective maintains focus and improves team alignment.
90-Day Growth Roadmap
A longer roadmap helps teams avoid reactive change patterns and align upgrades with evidence. Roadmaps reduce context switching and support cleaner planning.
Days 1-30: Baseline and First Optimization Loop
Launch one focused page, validate tracking, and complete one full optimization cycle. The goal is not maximum conversion; the goal is stable interpretability.
Days 31-60: Trust and Channel Expansion
Add stronger proof and objection handling, then introduce one source-specific opening variant. Keep page backbone stable to preserve learning continuity.
Days 61-90: Scale Readiness Review
Evaluate whether free-plan constraints are limiting outcomes. If constraints remain manageable, continue compounding with existing setup.
If constraints are clearly blocking growth, prepare a structured expansion plan that preserves proven messaging and architecture. Continuity protects past learning during technical expansion.
This roadmap keeps teams focused on measurable progress rather than ad hoc redesigns. Measured progress is easier to defend across cross-functional stakeholders.
Upgrade Decision Framework
Upgrading too early increases fixed cost without guaranteed conversion gains. Upgrading too late can block growth if workflow or integration limits become real bottlenecks.
Use explicit triggers for upgrade decisions. Trigger-based upgrades protect budget and reduce emotionally driven tool changes:
- Branding requirements that materially affect trust.
- Integration requirements that affect lead handling or activation quality.
- Collaboration needs that exceed current workflow controls.
- Reporting depth required for paid channel efficiency.
- Scale constraints affecting performance or publishing reliability.
When none of these triggers are active, keep optimizing the current setup. Free does not mean weak if execution discipline is strong.
When triggers are active, migrate with continuity. Keep proven structure and copy logic so you are expanding capability, not restarting strategy.
Implementation Toolkit for the Next 60 Days
Most teams know what they should do, but they still stall because execution steps are not concrete enough. A lightweight implementation toolkit closes that gap by turning strategy into repeatable actions.
This toolkit is designed for small teams with limited time. It focuses on high-leverage routines that can be completed without long meetings or engineering dependencies.
Weekly Operating Card
A weekly operating card is a one-page checklist that keeps everyone aligned. It should include one hypothesis, one planned change, one primary metric, one guardrail, and one owner.
The card works because it makes priorities explicit. When priorities are explicit, teams avoid impulsive edits that break interpretability.
At the end of the week, record outcome and decision. If the change did not produce a clear result, document why and what variable to isolate next.
Source-by-Source Message Matrix
A message matrix helps teams avoid generic opening copy across all traffic sources. Create a small table with columns for source type, intent state, leading pain point, trust cue, and primary CTA wording.
Keep the backbone structure constant while updating the first-screen angle by source. This preserves analytical clarity while improving message relevance.
Review the matrix monthly. Source behavior often shifts as campaigns mature or as audience familiarity increases.
Proof Update Queue
Proof fatigue is a real issue on recurring campaigns. Repeated testimonials can become invisible to returning visitors even if the original content is strong.
Maintain a rotating queue with three proof types: outcome proof, process proof, and reliability proof. Outcome proof supports aspiration, process proof supports understanding, and reliability proof supports trust under real constraints.
Update at least one proof block each month. Small refresh cycles usually outperform occasional large rewrites.
Objection Signal Pipeline
Objections should be collected systematically from support conversations, sales calls, and form comments. Place recurring objections into a priority queue based on frequency and conversion impact.
High-frequency objections belong in core sections, not only in FAQ. Low-frequency objections can stay in FAQ until patterns strengthen.
Link each objection update to a measurable expected effect. This turns content maintenance into a decision-driven process instead of a writing task.
Variant Readiness Checklist
Before launching a variant, run a short readiness check. Confirm that the control version is stable, the test variable is isolated, and the expected signal window is realistic.
Variants fail most often because teams change too much at once. Isolation is more important than volume in early-stage experimentation.
After launch, avoid additional structural edits until the decision window closes. Mid-test edits can invalidate conclusions.
Lightweight QA Protocol
A lightweight QA protocol should run before every major publish. It needs to be fast enough to use consistently and strict enough to catch high-impact issues.
Recommended checks include first-screen clarity, CTA hierarchy, trust cue placement, mobile readability, and tracking event integrity. Add one category-specific check based on your offer type.
Log QA outcomes in the same file as experiment notes. Keeping QA and experiment history together improves accountability and debugging speed.
Monthly Review Agenda
A monthly review should answer four questions. What improved, what degraded, what remained inconclusive, and what will be tested next.
Use evidence from source-level behavior and quality guardrails, not only aggregate conversion movement. Aggregate numbers can hide channel-level regression.
Close each review with one primary objective for the next cycle. Single-objective planning usually produces cleaner execution than multi-track agendas.
Handback Protocol for Team Transitions
When ownership shifts between contributors, knowledge loss can slow progress quickly. A handback protocol protects continuity during transitions.
Include current hypothesis, active variants, known friction points, and top three pending decisions. Keep the handback note concise and operational.
Teams that use handback notes recover execution speed faster after role changes. This matters for lean organizations where contributors often wear multiple hats.
Reliability Layer for No-Cost Operations
Reliability is not only a product concern. Website operations also need reliability in publishing, tracking, and message consistency.
Create a simple reliability layer with three controls: publish checklist, rollback plan, and post-publish validation window. These controls reduce the risk of conversion disruption during fast updates.
A rollback plan can be minimal. It only needs clear steps to restore the last stable version if a major issue appears.
Campaign-to-Evergreen Feedback Loop
Campaign pages are useful experimentation environments. Evergreen pages are useful for stable trust and long-term discovery.
The strongest workflow moves tested wins from campaigns into evergreen assets. This turns short-term experiments into durable conversion improvements.
Track which campaign insights were promoted and when. Promotion tracking helps teams understand which improvements created lasting value.
Risk Register for Growth Pages
A small risk register helps teams anticipate predictable failure points. Common risks include broken tracking events, stale proof, mobile regressions, and pricing ambiguity.
Assign a probability and impact score to each risk. Then define one prevention action and one recovery action.
Risk registers should stay short. The objective is operational awareness, not documentation overhead.
Editorial Stability Rules
Editorial stability means keeping core message integrity while testing smaller framing changes. Without stability rules, teams can accidentally invalidate successful positioning.
Define fixed elements for each cycle, such as core offer sentence and primary CTA path. Define variable elements separately, such as headline framing or proof ordering.
Stability rules protect learning. They also prevent stakeholder debates from drifting into low-impact style preferences.
Decision Logging Format
Decision logs should be concise and comparable across weeks. A strong format includes date, hypothesis, change summary, primary metric result, guardrail result, and final decision.
Use consistent wording for decisions: keep, iterate, revert, or archive. Consistency improves searchability and makes pattern analysis easier over time.
Archive low-value experiments with short notes. These notes reduce repeat mistakes when new contributors join.
Scaling Trigger Dashboard
A scaling trigger dashboard combines your upgrade triggers in one place. Include branding constraints, integration constraints, workflow constraints, and reporting constraints.
Review triggers monthly, not daily. Trigger noise can create premature tool changes if reviewed without enough context.
When two or more major triggers become persistent, begin a controlled expansion plan while preserving proven conversion logic.
Practical Output Standard
Every weekly cycle should produce a practical output artifact. That artifact can be an updated page section, a variant result note, or a corrected trust block.
Output standards prevent analysis-only cycles that consume time without improving conversion quality. They also keep momentum visible to stakeholders.
At month end, summarize three wins and three unresolved constraints. This summary becomes the input for the next planning cycle.
Scenario Playbooks
Scenario A: Traffic High, Conversions Flat
This usually indicates first-screen mismatch or weak trust placement. Visitors arrive but do not gain enough confidence to continue.
A practical response is to tighten audience-outcome language and move proof closer to action zones. This often improves conversion confidence without a full page rebuild.
Scenario B: CTA Clicks Up, Completions Down
This pattern often signals overpromising in early sections or friction in form flow. Users show curiosity but lose confidence at commitment points.
A practical response is to align promise strength with offer reality and simplify post-click steps. Alignment reduces expectation mismatch and downstream friction.
Scenario C: Conversion Up, Lead Quality Down
Higher volume with lower relevance usually means qualification boundaries are too weak. The page attracts too broad an audience.
A practical response is to add explicit fit criteria and scope limits near the first decision stages. Better qualification usually improves long-term conversion economics.
Scenario D: Organic Performs, Social Underperforms
Organic visitors often have clearer intent than social visitors. A single opening narrative can under-serve one channel.
A practical response is to keep structure fixed and run a social-specific opening variant with stronger context and trust cues. Structural consistency keeps the test easier to interpret.
Scenario E: Fast Edits, Slow Learning
High edit velocity with minimal insight usually means tests are not controlled. Multiple simultaneous changes reduce interpretability.
A practical response is to reduce changes per cycle and require one written hypothesis for every significant update. Fewer simultaneous changes produce clearer learning.
Common Mistakes and Fixes
Mistake 1: Tool-first planning
Fix: define audience, offer, and primary action before selecting templates. This sequencing prevents mixed-intent page architecture.
Mistake 2: Multi-goal hero sections
Fix: keep one dominant CTA and align copy around one conversion objective. Clear hierarchy reduces hesitation during first visits.
Mistake 3: Proof isolated in low-attention zones
Fix: position context-rich proof near forms and commitment moments. Proof timing can influence completion as much as proof quality.
Mistake 4: Mobile treated as secondary QA
Fix: run mobile validation before every publish decision. Real-device checks catch issues desktop previews miss.
Mistake 5: Testing many variables simultaneously
Fix: isolate one major variable per cycle and keep a clear test log. Controlled variation improves interpretability and speed.
Mistake 6: Upgrading based on perception
Fix: upgrade only when measured constraints block meaningful outcomes. Evidence-first timing preserves budget efficiency.
Mistake 7: Static copy despite evolving objections
Fix: refresh objection and FAQ sections monthly using real user feedback. Fresh objection handling prevents silent conversion decay.
Mistake 8: No source-level analysis
Fix: review behavior by channel and adapt opening messaging accordingly. Channel-level differences often explain aggregate volatility.
Mistake 9: Overuse of generic claims
Fix: replace abstract promises with mechanism-plus-outcome language. Mechanism clarity increases credibility for skeptical visitors.
Mistake 10: No ownership model
Fix: assign explicit message, proof, analytics, and QA responsibilities. Ownership clarity keeps rapid iteration reliable.
FAQ: No-Cost Website Builder Playbook
1) Can no-cost builders support serious business outcomes?
Yes, if launch structure, trust architecture, and testing discipline are strong. Execution quality matters more than plan tier in early stages.
2) How many pages should we launch first?
Start with one focused conversion page, then add supporting pages only after the core path is stable. Controlled expansion protects clarity while adding depth.
3) Which metric should we prioritize first?
Track qualified completion for your primary action. This metric is more useful than raw traffic volume.
4) Should we include pricing early?
Include enough pricing context to reduce uncertainty where pricing trust affects decisions. Price ambiguity is a common cause of late-stage drop-off.
5) How often should we update?
Weekly focused updates plus a monthly structured review usually deliver strong learning velocity. This cadence keeps experiments manageable and cumulative.
6) Is one CTA always best?
One dominant CTA is usually best for clarity. A secondary path can help when readiness levels differ, but hierarchy must remain explicit.
7) How can we improve lead quality quickly?
Add fit boundaries, clarify scope, and align proof with your target user profile. Better filtering improves quality even if volume dips temporarily.
8) Do we need advanced SEO tools to grow search traffic?
No. Clear structure, useful depth, and intentional internal links can produce meaningful results.
9) When should channel variants be added?
Add variants when one channel underperforms consistently despite stable traffic quality. Start with one variant to keep measurement clean.
10) What is the fastest high-impact change?
Rewrite the first screen to improve audience fit clarity and strengthen trust near the primary action. This is usually the fastest high-impact improvement.
11) How do we know if upgrades are necessary?
Use measurable constraints as triggers, such as integration gaps or workflow limits that block outcomes. Trigger-based decisions reduce unnecessary complexity.
12) What is the biggest launch mistake?
Publishing without one clear objective and one clear review loop. Lack of objective clarity usually creates noisy metrics and reactive edits.
Final Takeaway
No-cost builder workflows can produce strong, scalable outcomes when they are run as disciplined operating systems. Fast launch capability is valuable only when paired with clear decision structure, trust placement, and controlled iteration.
Teams that publish quickly, measure honestly, and improve in tight cycles usually outperform teams that overbuild early. The winning formula is straightforward: one objective, one page backbone, one test at a time, and one evidence-based decision after each cycle.
Related Blog Posts
- Easy web site design made simple for startups
- Build Beautiful Websites Without Coding: A Practical 2026 Guide for Fast, High-Quality Results
- Create Your Web Presence With Simple Drag-and-Drop: A Practical 2026 Playbook
- Free-First Startup Website Launches: How to Move Fast Without Creating Conversion Chaos

