Table of Contents
- Why Fast Page Projects Underperform
- 30-Day Execution Plan
- Risk Management and Recovery Playbooks
- Common Failure Modes and Fast Fixes
- FAQ
Most teams do not fail because they cannot publish quickly. They fail because each release changes too many things at once, weakens message clarity, and makes results harder to interpret. The page goes live, traffic arrives, and metrics move, but nobody can explain exactly why performance improved or declined.
High output without structured decision logic creates noise. Teams see activity and feel progress, but conversion quality remains unstable across channels, devices, and audience segments. This instability is expensive because it increases rework and slows learning.
A reliable page-build system should do more than publish fast. It should help users understand relevance quickly, trust claims earlier, and choose the next action with low friction. It should also generate clean data so teams can decide what to keep, what to remove, and what to test next.
Unicorn Platform is useful for this model because it supports reusable sections, quick iteration, and clear ownership workflows. The platform speed becomes a competitive advantage when teams pair it with message discipline, quality gates, and measurable hypotheses.
sbb-itb-bf47c9b
Quick Takeaways
Conversion Optimization Strategies
- Speed helps only when structure stays stable.
- First-screen clarity drives more outcomes than decorative complexity.
- Proof should be positioned near claims, not buried late in the page.
- One dominant action per variant usually improves conversion confidence.
- Form fields should be tied to real routing decisions.
- Device QA should be mandatory before scaling traffic.
- One-variable releases produce cleaner insights than broad redesigns.
- Shared ownership and release gates protect quality under pressure.
Why Fast Page Projects Underperform
The most common breakdown is strategic drift. Teams start with one objective, then add extra audiences, extra offers, and extra CTAs as launch pressure rises. By release day, the page tries to satisfy everyone and persuades no one with confidence.
The second breakdown is proof misalignment. Strong claims are made early, but supporting evidence appears too late or lacks context. Users are asked to commit before uncertainty is reduced, so hesitation rises at the most important moments.
The third breakdown is operational inconsistency. Design, copy, and growth edits happen in parallel without a common conversion spine. Sections look polished in isolation but fail as a sequence.
The fourth breakdown is measurement weakness. Teams track only top-level conversions, then assume quality is improving. Without downstream checks, low-fit volume can be mistaken for success.
The Decision Spine for High-Performing Pages
A reliable page follows one decision spine: relevance, mechanism, confidence, and action. This order reflects how users evaluate risk in real time.
Relevance answers who this is for and why it matters now. Mechanism answers how value is created. Confidence answers why the promise is believable. Action answers what to do next and what to expect after the click.
When this spine is preserved, teams can test message depth and proof formats without breaking user orientation. When the order shifts randomly, attribution becomes messy and optimization slows.
For teams that need a practical baseline for section order, this high-converting landing page structure framework is useful for keeping narrative flow consistent.
Discovery: Define Audience and Intent Before Drafting
Strong pages begin with decision context, not visual layout. Teams should define one primary audience, one problem state, and one expected transformation before writing headline options.
If audience definition is vague, everything else becomes vague. Proof selection weakens, CTA intensity drifts, and form logic becomes generic.
Discovery should also include intent stage mapping. Cold traffic needs orientation and low-friction progression. Warm traffic needs stronger mechanism and proof. Decision-stage traffic needs confidence and direct action clarity.
Discovery Checklist
- Who is the highest-priority audience for this release?
- What single outcome matters most to that audience now?
- Which objections are most likely before conversion?
- What proof can resolve those objections credibly?
- What next step matches this intent stage?
This checklist keeps production focused and reduces late-stage rewriting.
First-Screen Architecture: The Highest-Leverage Section
The first screen should resolve three questions in seconds: is this relevant, what value can I expect, and what action should I take now. If one answer is unclear, deeper sections lose impact.
Strong first-screen copy uses role context and concrete outcomes. Weak first-screen copy relies on broad claims that sound confident but require interpretation.
The first screen should include one concise trust cue, such as an outcome snapshot, recognizable context, or concrete implementation signal. This lowers uncertainty without overloading the reader.
First-Screen Quality Questions
- Is the audience fit obvious without scrolling?
- Is the promise specific enough to evaluate quickly?
- Is one primary action unmistakable?
- Is there an immediate reason to trust the promise?
If any answer is no, revise first-screen content before changing lower sections.
Mechanism Clarity: Explain How the Promise Works
Mechanism clarity reduces skepticism and helps users assess fit realistically, especially when paired with tools like heavy equipment software that streamline workflows and provide operational insights.
A useful mechanism section explains process in plain language: starting state, workflow change, and expected output. This can be communicated with short steps, compact visuals, or a concise before/after model.
Mechanism detail should match audience readiness. Early-stage visitors need a clear overview. Advanced visitors may need deeper implementation notes.
Teams should avoid jargon-heavy mechanism descriptions that increase cognitive load without increasing confidence.
Value Block Design: Translate Features Into Decisions
Feature lists are rarely persuasive on their own. Users care about what becomes easier, faster, or safer after adopting the offer.
Value sections should frame outcomes as decisions users can make better. This shifts copy from marketing language to practical utility.
A strong value block includes one use-case signal, one measurable effect, and one implementation condition. This helps users connect abstract capability to real context.
When value framing is practical, both conversion quality and downstream satisfaction improve.
Trust System Design: Evidence, Placement, and Freshness
Trust is not a single testimonial strip. It is a system of proof cues positioned where hesitation is likely.
Use layered trust: short evidence near early claims, contextual social proof near mechanism blocks, and reliability signals near final actions. This sequence supports confidence without creating heavy reading burden.
Proof freshness is essential. Outdated metrics, old screenshots, and stale customer stories reduce credibility even when structure is strong.
Teams should assign proof ownership and refresh cadence so evidence quality stays current under rapid release cycles.
For teams that need tactical post-launch iteration ideas, this actionable landing-page optimization guide can help prioritize high-impact updates.
CTA Strategy by Readiness Stage
Calls to action should reflect user intent, not team preference. Mixing low-friction and high-friction actions with equal visual weight usually increases hesitation.
A cleaner model uses one dominant action per variant and one optional fallback route for users who need a smaller commitment step.
CTA language should describe user benefit and immediate next step. Generic labels make users think harder, which slows decisions.
Readiness-Based CTA Mapping
- Discovery stage: learn or preview action
- Evaluation stage: compare or validate action
- Decision stage: start, book, or buy action
This mapping helps teams align action intensity with actual visitor state.
Form and Qualification Logic
Form design should support routing quality without suppressing completion unnecessarily. Every required field should map to a real downstream decision.
When fields do not affect prioritization, personalization, or follow-up path, they often add friction with limited value.
A strong first-step form usually captures essentials plus one high-signal qualifier. Additional context can be gathered later through confirmation or follow-up steps.
Qualification Design Rules
- Keep first-step effort low.
- Ask for information only when needed for immediate routing.
- Defer deep qualification until intent is confirmed.
- Explain why requested fields matter.
These rules improve both conversion and handoff efficiency.
Mobile Experience Engineering
Mobile performance is not only about responsive layout. It is about maintaining decision clarity under small-screen constraints.
Mobile users should see audience fit, value signal, and primary action quickly. If these elements fall below deep scroll depth, conversion confidence drops.
Form interactions should be tested with real keyboards and real devices. Label behavior, validation feedback, and submit flow often break in ways desktop review cannot detect.
Teams should also monitor mobile quality by source. Social, search, and email traffic can expose different friction patterns.
Performance and Speed Budgeting
Page speed matters because delays can interrupt trust and reduce action momentum. Teams should prioritize time-to-meaningful-value, not only full asset completion. This impact is measurable. Research shows that conversion rates drop significantly as load time increases, with the highest conversion rates occurring on pages that load within the first few seconds, reinforcing the importance of strict performance budgets in high-conversion environments.
Critical copy, trust cues, and primary action should load early. Secondary visuals can be deferred when needed.
A practical speed budget should define acceptable thresholds by device class and connection quality. This keeps performance decisions measurable rather than subjective.
Speed improvements should be evaluated alongside conversion quality. Faster load with weaker clarity is not a net win.
Tracking and Attribution Architecture
Reliable optimization requires reliable tracking. Event naming, route mapping, and funnel definitions should be stable across variants.
Teams should track both behavior and quality signals: CTA interactions, form starts, completions, qualified outcomes, and downstream progression.
Attribution improves when variants change one major variable at a time. If multiple structural changes are launched together, performance shifts become hard to explain.
Tracking Essentials
- clear event taxonomy by funnel stage
- source and device dimensions on key events
- qualification markers tied to conversion events
- guardrail events for early quality decline detection
These basics improve forecasting and reduce analysis rework.
Release QA: From Checklist to Gate
Quality checks should be release gates, not optional reminders. A page should not scale traffic until critical checks are passed.
A practical gate includes message clarity verification, proof relevance confirmation, CTA and form routing checks, mobile interaction checks, and analytics validation.
If one gate fails, launch should pause. Teams that enforce this consistently reduce costly regressions and improve trust in performance data.
Ownership Model for Fast Teams
Speed creates quality risk when ownership is unclear. A simple role model prevents drift.
Define a messaging owner, proof owner, performance owner, and QA owner. Each owner should have explicit responsibilities and sign-off boundaries.
This model reduces ambiguity during rapid cycles and makes recovery faster when issues emerge.
For early-stage teams balancing speed and structure, this startup-focused landing-page creation guide can help align ownership with execution reality.
Experimentation Framework: One Variable, Clear Learning
Controlled experimentation outperforms broad redesign when the goal is reliable growth. Each release should include one hypothesis, one primary metric, and one guardrail metric.
Primary metrics drive progress direction. Guardrails protect downstream quality and prevent false wins.
Teams should maintain a shared test log with hypothesis, change scope, expected behavior, observed result, and final decision. This creates reusable learning over time.
Useful Test Types
- headline specificity versus emotional framing
- proof format and placement variation
- CTA wording by readiness stage
- first-step form depth adjustments
- objection-handling section placement
These tests produce high-value insights when scope stays controlled.
Component Library Strategy
Teams move faster when they maintain a component library mapped to decision stages. Rebuilding from zero every cycle increases effort and inconsistency.
A practical library includes approved hero modules, mechanism modules, trust modules, CTA modules, and form modules, each with clear usage rules.
Modules should be promoted into the library only after repeated positive performance in distinct contexts. This keeps the library practical and prevents clutter.
Library Governance Cadence
- weekly review of recent test outcomes
- monthly promotion or retirement of modules
- quarterly library cleanup and taxonomy updates
This cadence keeps production speed high without quality drift.
Cross-Functional Alignment
Page quality depends on downstream teams as much as on page editors. If marketing and sales define quality differently, conversion systems weaken.
Teams should agree on qualification definitions, response SLAs, and context fields required for first outreach.
A short weekly alignment sync can close feedback loops quickly. If sales reports recurring confusion, page messaging should be updated in the next cycle rather than deferred.
Cross-functional alignment is most effective when it is metric-driven and tied to concrete page decisions.
Risk Controls and Recovery Playbooks
Fast release programs need explicit risk controls. Without them, small issues can compound before detection.
Risk controls should cover technical failures, messaging regressions, and quality guardrail declines. Recovery playbooks should define ownership, rollback triggers, and retest steps.
Teams with pre-defined recovery paths resolve issues faster and avoid panic-driven edits that create additional noise.
Core Risk Controls
- anomaly alerts on conversion and guardrail events
- integration failure alerts for form routing
- documented rollback rules by issue type
- post-incident review templates for learning capture
These controls protect both performance and team confidence.
Scenario: Startup With High Activity, Low Insight
A startup published frequent page updates but could not explain performance changes clearly. Each release mixed headline changes, proof updates, and CTA tweaks.
Audit showed strong effort but weak experiment control. The team then moved to a single-variable release model in Unicorn Platform with shared ownership and release gates.
Within two months, decision clarity improved and qualified conversion rose. The biggest gain came from cleaner testing, not from more creative output.
Scenario: Agency Handling Multi-Channel Variation
An agency running campaigns across search, social, and email used one broad template for all traffic. Results were inconsistent and difficult to optimize.
They adopted source-aware variants with stable structure and intent-specific message emphasis. They also implemented shared QA gates and standardized tracking events.
Over one quarter, performance became more predictable and rework declined because winning modules were reused across accounts.
30-Day Execution Plan
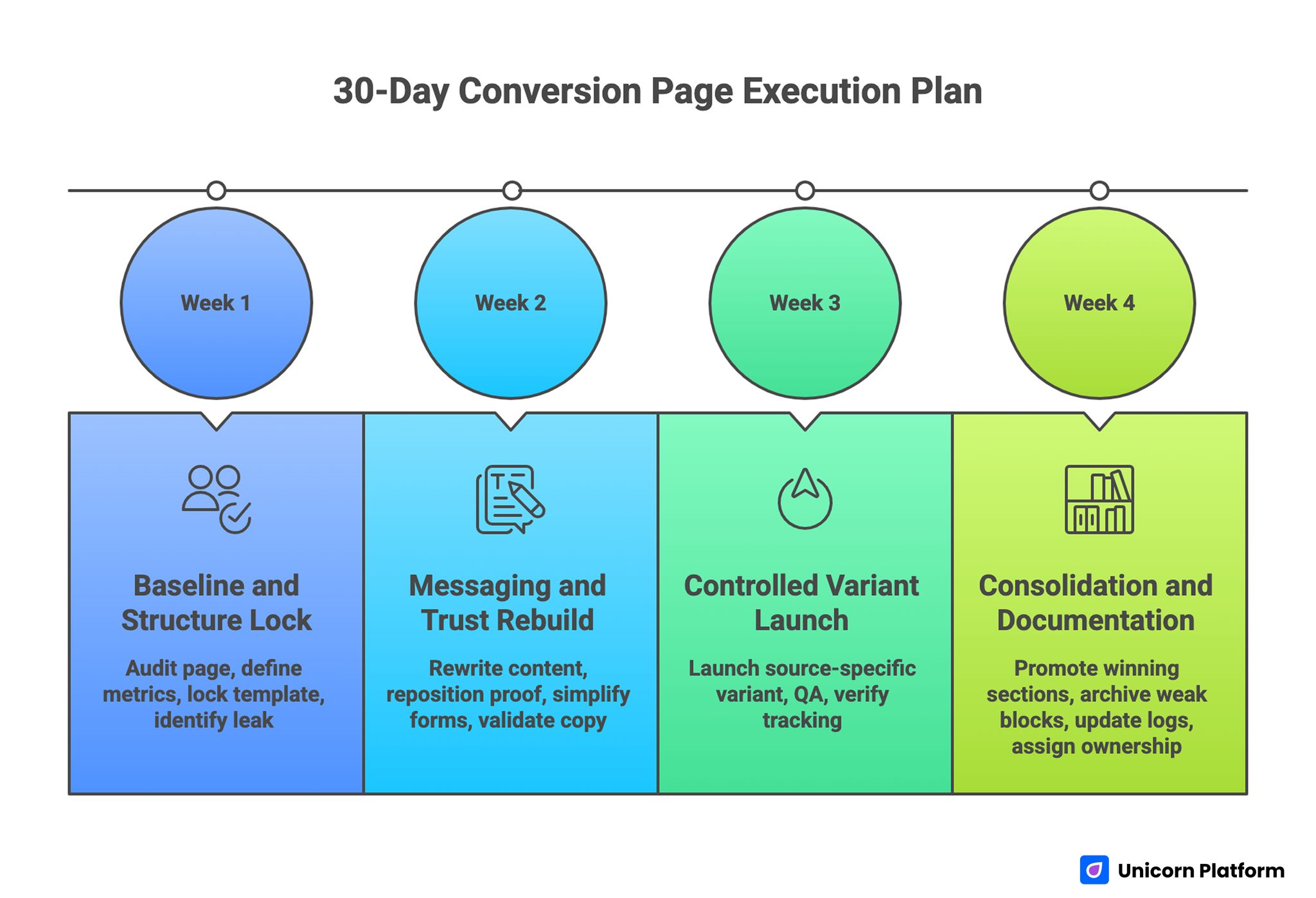
30-Day Conversion Page Execution Plan
Week 1: Baseline and Structure Lock
Audit one high-priority page against relevance, mechanism, confidence, and action sequence. Identify the largest leak by source and device.
Define one primary metric and one guardrail metric for the next cycle. Lock one structural template and remove competing CTA routes.
Week 2: Messaging and Trust Rebuild
Rewrite first-screen content for audience fit and concrete outcome. Reposition proof modules near key claims.
Simplify form inputs to routing essentials and validate copy clarity across mobile and desktop.
Week 3: Controlled Variant Launch
Launch one source-specific variant with one major message change. Keep structure stable to preserve attribution quality.
Run full release QA and verify tracking before increasing spend.
Week 4: Consolidation and Documentation
Promote winning sections to the template library. Archive weak blocks and update test logs with explicit outcomes.
Assign monthly proof refresh ownership and define next-cycle hypothesis priorities.
90-Day Scale Plan
Month 2: Expand by Readiness Segment
Build controlled variants for discovery, evaluation, and decision traffic with a shared structural backbone.
Develop reusable modules for each decision stage and document where each module should and should not be used.
Month 3: Operationalize Reliability
Formalize release gates, role permissions, and rollback thresholds tied to guardrail decline.
Require decision logs for high-impact changes so learning compounds across teams and campaigns.
At this stage, scale should come from system reliability rather than constant layout redesign.
Operating Economics: Speed, Cost, and Quality Together
Fast production should lower total campaign cost, but only if quality is preserved. A cheap release that creates low-fit leads or unclear routing can cost more downstream than a slower release with stronger qualification.
Teams should evaluate economics across three layers. The first layer is build efficiency, including time from brief to publish and number of review cycles required. The second layer is conversion efficiency, including qualified action rate by source and device. The third layer is downstream efficiency, including sales acceptance, activation quality, and early pipeline velocity.
When these layers are reviewed together, teams can distinguish between true efficiency gains and superficial speed gains. This prevents the common pattern where output volume rises while business quality remains flat.
Practical Efficiency Signals
- cycle time from brief approval to stable release
- number of post-launch hotfixes per page
- qualified conversion ratio by traffic source
- time-to-first-response after submission
- accepted-lead or activation progression rate
Teams that track these signals monthly usually make better budget decisions than teams focused only on top-line conversion.
Capacity Planning for Small and Growing Teams
High release velocity creates hidden workload in QA, diagnostics, and follow-up alignment. Many teams plan capacity for publishing but under-plan capacity for maintenance and learning.
A practical planning model separates weekly capacity into four buckets: net-new builds, optimization updates, QA checks, and maintenance tasks. This prevents urgent launches from consuming all available time and leaving critical quality work unfinished.
Capacity planning should also include ownership bandwidth. If one role is overloaded, quality bottlenecks appear quickly and release risk increases.
Capacity Questions to Review Monthly
- How many high-impact launches can be supported without skipping QA?
- Which owner role is consistently overloaded?
- How much time is reserved for test analysis and documentation?
- Which maintenance tasks are repeatedly deferred?
Answering these questions keeps growth pace sustainable under pressure.
Component Library Governance for Consistent Output
Reusable modules are one of the strongest multipliers for fast teams, but only when governance is clear. Without governance, libraries become crowded with unvalidated sections and inconsistent styling patterns.
A healthy library is organized by decision stage, not by visual preference. Teams should maintain modules for orientation, mechanism, proof, objection handling, and action. This makes assembly faster and keeps narrative order coherent.
Promotion rules are essential. New modules should enter the approved library only after repeated positive performance in different campaign contexts. This protects teams from scaling one-off wins.
Library Lifecycle Rules
- Draft modules: can be used in controlled tests only
- Candidate modules: have one positive cycle and need validation
- Approved modules: have repeated positive results with guardrails intact
- Retired modules: no longer reliable or context-relevant
This lifecycle reduces template drift and keeps future launches predictable.
Collaboration Workflow Across Marketing, Design, and Sales
Page performance depends on cross-functional alignment. If marketing optimizes for submissions while sales optimizes for readiness, teams can unintentionally work against each other.
Alignment starts with shared definitions for qualified conversion, response SLAs, and required context for first outreach. These definitions should be documented and reviewed regularly, not assumed.
A short weekly quality sync can resolve most misalignments quickly. Focus the sync on one page family, one friction point, and one decision for the next cycle.
Collaboration Rituals That Work
- 20-minute weekly page-quality review
- shared dashboard for primary and guardrail metrics
- sales feedback summary tied to specific sections
- explicit owner assignment for next actions
These rituals keep communication practical and reduce decision latency.
Attribution and Measurement Architecture
Reliable optimization requires stable measurement architecture. Event naming, funnel stage definitions, and variant metadata should be consistent across releases.
Teams should avoid redefining success criteria every cycle. A stable primary metric and stable guardrail framework improves comparability and confidence in conclusions.
Attribution quality improves when releases are scoped to one major change. If multiple structural elements move together, observed shifts may be real but difficult to explain.
Measurement Layers to Maintain
- Page behavior layer: clicks, starts, completions
- Quality layer: qualification fit, response engagement
- Outcome layer: opportunity, activation, revenue progression
This layered approach prevents local optimization from hurting broader outcomes.
Risk Management and Recovery Playbooks
Fast programs need pre-defined recovery logic. Without it, performance drops trigger reactive edits that increase noise and delay diagnosis.
Recovery playbooks should define failure categories, owner responsibilities, rollback thresholds, and retest steps. Teams should know what to do before an incident occurs.
A useful incident model includes immediate containment, root-cause validation, controlled rollback, and a short post-incident learning review. This model protects both performance and team confidence.
Critical Recovery Triggers
- significant decline in guardrail metric versus baseline
- form routing or integration failures
- sharp mobile conversion drop on key sources
- unexpected no-show or low-fit spikes after release
Trigger-based response keeps recovery fast and disciplined.
Compliance, Privacy, and Trust Operations
Trust is not only about testimonials and claims. For many audiences, trust also depends on transparent data practices and predictable communication behavior.
Forms should collect only information needed for routing and follow-up. Data usage expectations should be clear near submission points, especially when campaigns involve sensitive categories or regulated markets.
Teams should periodically review consent language, policy links, and follow-up promises to ensure alignment with actual behavior. Mismatch between stated and actual handling can damage brand trust quickly.
Trust Operations Checklist
- clear purpose statement for collected data
- visible policy access near form submission
- realistic follow-up timing commitments
- consistent confirmation messaging across channels
These checks support conversion by reducing perceived risk.
Implementation Worksheet for the Next Sprint
A short worksheet can improve execution quality before any design edits begin. Start with one sentence for audience fit, one sentence for promised outcome, and one sentence for next-step expectation.
Then map top objections to sections and assign one proof element to each objection. Define one primary metric and one guardrail metric before publishing changes.
Finally, confirm owner assignments for messaging, proof, QA, and analytics validation. Teams that complete this worksheet consistently tend to ship cleaner experiments and reduce rework.
Post-Launch Review Loop for the First 14 Days
The first two weeks after release usually determine whether a new page variant becomes a reliable asset or a short-lived experiment. Teams that wait until end-of-month reporting often miss early quality signals and lose time they could have used for targeted improvements.
A practical day-by-day review loop keeps analysis focused without creating overhead. On day one, validate event integrity and basic routing behavior. On day three, review device-level interaction data and early source fit signals. On day seven, evaluate primary metric direction and guardrail stability. On day fourteen, decide whether to scale, iterate, or retire the variant.
This structured timeline helps teams separate technical issues from message issues. It also prevents overreaction to early noise while still enabling fast recovery when true problems appear.
Day 1 to Day 3 Priorities
- confirm analytics and form-routing events are firing correctly
- verify confirmation and follow-up continuity across channels
- check mobile interaction quality on high-volume devices
- review early bounce and drop-off signals by source
If technical or routing issues appear here, fix before making copy or design conclusions.
Day 7 Evaluation Questions
By day seven, teams usually have enough directional data for early judgment. Ask:
- Did primary conversion behavior improve versus baseline?
- Did guardrail quality remain stable?
- Which sections show strongest engagement change?
- Are channel-level outcomes consistent with hypothesis?
These questions keep teams focused on actionable interpretation rather than raw volume excitement.
Day 14 Decision Framework
At day fourteen, choose one path explicitly: scale, iterate, or retire.
- scale if primary metric improves and guardrails remain healthy
- iterate if direction is promising but one friction point persists
- retire if quality signals remain weak after targeted fixes
Every decision should be logged with rationale and next steps. This creates reusable knowledge and reduces repeated testing mistakes.
What to Document in the Review Log
- variant objective and target audience
- launch date and hypothesis
- key observations from day 1, 3, 7, and 14
- final decision and owner for next action
- open risks to monitor in the next cycle
Teams that follow this review loop consistently tend to improve faster because each release produces clear operational learning, not just isolated metric snapshots.
Common Failure Modes and Fast Fixes
1) Broad Opening Copy
Users cannot quickly determine fit. Replace broad language with role-specific outcomes and clearer context so relevance is obvious in the first screen.
2) Mechanism Confusion
Users do not understand how value is produced. Add concise step-based mechanism explanation and keep workflow language practical.
3) Delayed Proof
Trust appears after decision points. Move evidence closer to major claims and actions so confidence forms before commitment.
4) CTA Overload
Multiple equal actions split intent. Keep one dominant route and one controlled fallback to reduce hesitation.
5) Form Friction
First-step forms request too much. Capture essentials first and defer deeper qualification until intent is clear.
6) Mobile Oversights
Desktop reviews miss high-impact interaction issues. Enforce real-device QA before every release, including slower-network checks.
7) Channel Mismatch
One message serves all sources and underperforms. Adapt framing by source while preserving structure for clean attribution.
8) Weak Confirmation Experience
Users convert without clear next-step guidance. Add immediate confirmation and expectation clarity to preserve conversion momentum.
9) Top-Line Metric Bias
Conversion volume rises while quality declines. Pair primary metrics with downstream guardrails so hidden quality losses are detected quickly.
10) Ownership Ambiguity
Fast edits create drift. Define release roles and enforce sign-off boundaries before scaling traffic.
Pre-Launch QA Checklist
Confirm first-screen fit clarity, mechanism transparency, trust adjacency, and one dominant action route.
Validate form behavior, mobile interaction quality, and confirmation continuity on real devices.
Verify event instrumentation for primary and guardrail metrics before scaling. Require final QA sign-off.
FAQ: Conversion Page Build Systems
What should teams optimize first?
Start with first-screen clarity and proof placement. These usually create the fastest quality gains because they shape early trust.
Should teams redesign fully every month?
Usually no. Controlled modular updates produce cleaner learning and lower rework risk. Frequent full redesigns tend to hide causes behind too many simultaneous changes.
How many CTAs should one variant include?
One dominant action and one fallback path are typically enough for clear routing. More equal-priority actions usually dilute intent and lower confidence.
How much form data should be requested first?
Only routing-critical fields. Additional context should be collected after intent is confirmed. This keeps completion high while preserving qualification quality.
Is mobile QA really necessary for B2B pages?
Yes. Even B2B audiences often discover and evaluate on mobile before converting later. Skipping mobile checks can silently degrade high-value traffic performance.
What is the most common trust mistake?
Making strong claims without adjacent, contextual evidence. Claims and proof should appear together so users can evaluate credibility quickly.
How often should proof be refreshed?
Monthly for active campaigns and quarterly at template level. Fast-changing offers may require additional refreshes during launch periods.
How do teams avoid testing noise?
Use one major variable per cycle and log hypotheses before launch. Clear scope and documentation make results easier to trust.
What metrics should guard conversion quality?
Use a primary conversion metric plus a downstream quality guardrail such as accepted lead rate or activation completion.
What creates compounding improvement over time?
Stable structure, disciplined experimentation, clear ownership, and shared decision logs. Compounding gains come from consistent execution, not constant reinvention.
Final Takeaway
High-performing page programs are built on structured decision flow, trust-aware messaging, and operational discipline. Speed matters, but reliability matters more.
Unicorn Platform enables teams to combine fast releases with controlled learning. Keep architecture stable, test with intent, and optimize for downstream quality so performance compounds instead of fluctuating.
Related Blog Posts
- Build Stunning Landing Pages Without Coding: A Practical Guide for Fast Results in 2026
- B2B Landing Page Conversion System in 2026: How Teams Build Qualified Pipeline at Scale
- Sales Campaign Landing Pages in 2026: How Teams Turn Promotional Traffic Into Reliable Revenue
- Example-Driven Conversion Page Systems in 2026: How Teams Turn Inspiration Into Reliable Results
