Table of Contents
- End-to-End Build Framework for AI Products
- Tooling and Stack Decisions That Matter Early
- 30-Day Launch Plan
- Common Failure Patterns and Fast Fixes
- FAQ
Launching an AI product is easier than ever and succeeding with one is still hard. Teams can assemble demos quickly, but many projects underperform after launch because users do not understand value, onboarding is unclear, or trust concerns appear too late.
The main challenge is not only model quality. The challenge is system quality across product, UX, messaging, and go-to-market execution. If one layer is weak, the entire funnel weakens.
A better approach treats the product and the acquisition experience as one connected workflow. Your core capability, your proof, and your landing-page narrative should reinforce the same promise from first visit to first value.
This guide explains how to do that step by step in 2026. It covers architecture decisions, no-code versus custom build paths, cost and timeline planning, trust guardrails, and launch operations in Unicorn Platform.
If budget planning is still open, this cost framework for building an AI app helps set realistic scope before you commit to stack decisions.
sbb-itb-bf47c9b
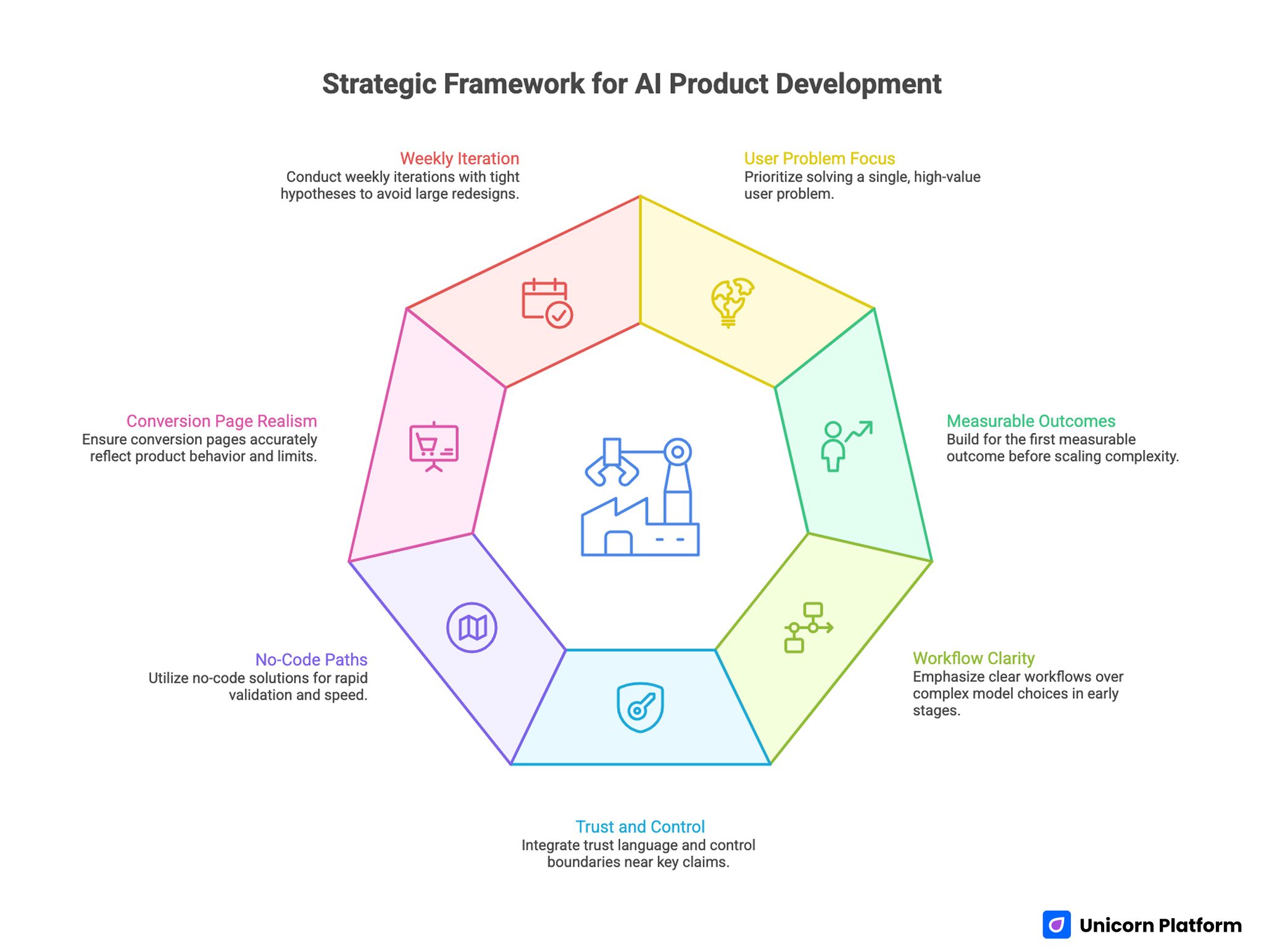
Quick Strategic Takeaways
AI Product Development Framework Showing Stages
- Start with one high-value user problem, not broad feature ambition.
- Build for first measurable outcome before scaling complexity.
- Model choice matters less than workflow clarity in early versions.
- Trust language and control boundaries should appear near key claims.
- No-code paths are useful when speed and validation matter most.
- Conversion pages should mirror real product behavior and limits.
- Weekly iteration with tight hypotheses beats large redesign cycles.
Why AI Product Launches Still Underperform
Most underperformance patterns are predictable. Teams ship a strong technical component and assume the market will infer value automatically. In practice, users need explicit context: what the product does, where it helps, and what it does not do.
A second issue is feature-first storytelling. Pages describe technology depth before they explain user outcomes, which increases cognitive load and lowers conversion confidence.
A third issue is trust sequencing. Data handling, reliability limits, and human oversight appear too late in the journey. By that point, many users already dropped.
When these gaps are corrected early, both activation quality and lead quality improve without major increases in traffic.
End-to-End Build Framework for AI Products
End-to-End Build Framework for AI Products
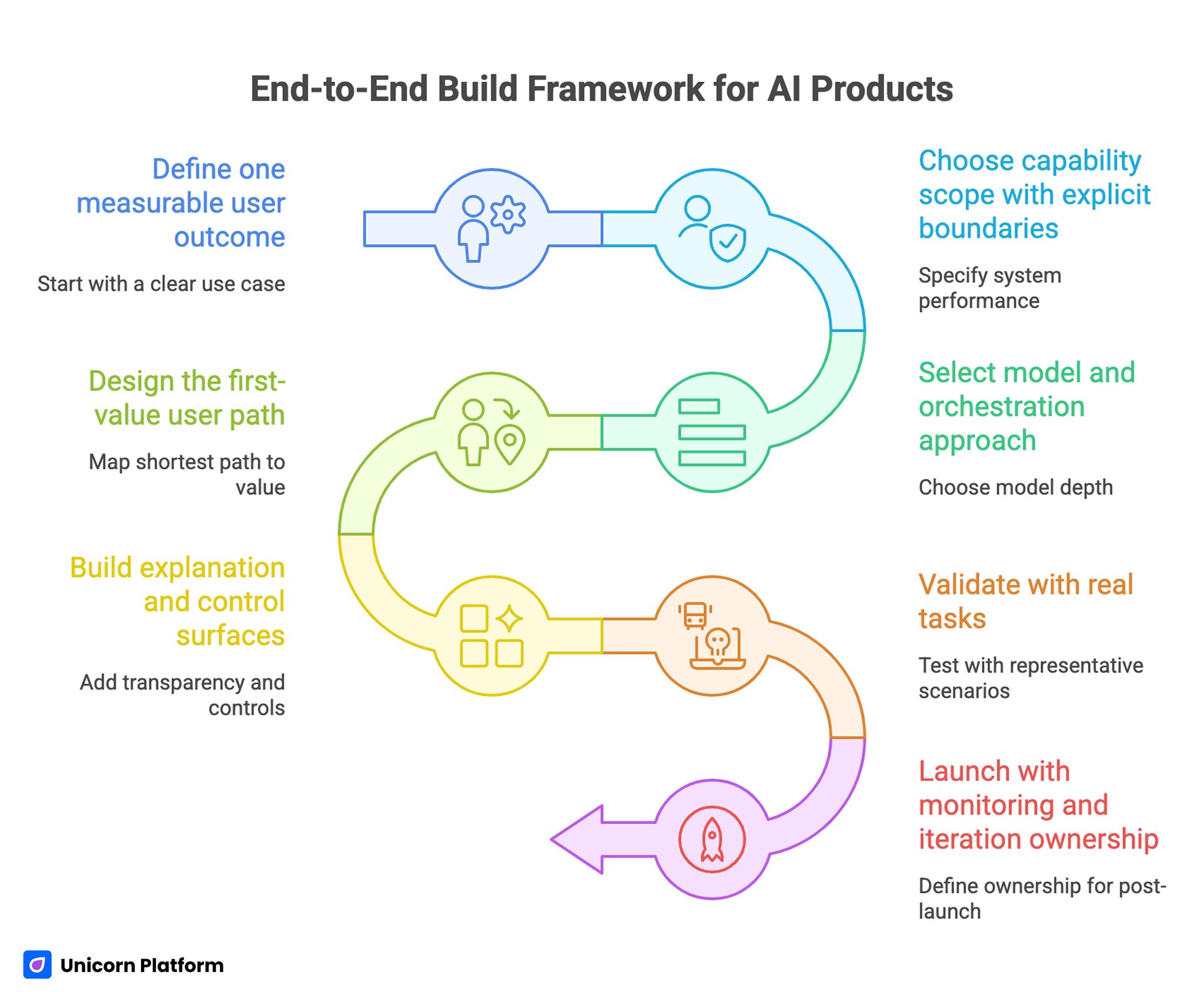
A reliable launch workflow has seven stages. The order matters because each stage reduces downstream risk.
1) Define one measurable user outcome
Begin with one use case that has clear business relevance. Avoid broad mission statements and define a concrete before-and-after condition your users care about.
2) Choose capability scope with explicit boundaries
Specify where the system should perform well and where users should not rely on it. Clear boundaries improve trust and reduce support burden.
3) Select model and orchestration approach
Choose model depth based on latency, cost, and reliability requirements. For many launches, a simpler architecture with strong prompt and retrieval discipline outperforms premature complexity.
4) Design the first-value user path
Map the shortest path from first interaction to meaningful output. If users cannot reach first value quickly, retention pressure increases.
5) Build explanation and control surfaces
Add transparency where it changes behavior: source context, confidence boundaries, editing controls, and fallback options.
6) Validate with real tasks
Test with representative user scenarios, not internal demos only. Real workflows expose friction that synthetic tests miss.
7) Launch with monitoring and iteration ownership
Define who owns performance metrics, model behavior review, and UX updates. Ownership clarity prevents post-launch drift.
This sequence is practical for startups and scalable for larger teams because it emphasizes measurable progress instead of abstract readiness.
Core Use Cases and What They Require
Different use cases need different quality controls. Grouping them correctly helps you avoid generic implementation decisions.
Personalization and recommendation workflows
These systems need strong input quality and transparent logic. Users should understand why they are seeing a recommendation, especially in high-stakes decisions.
Predictive analytics workflows
Prediction products require clear error communication and update cadence expectations. Confidence ranges and scenario limitations should be visible before users commit to outcomes.
Natural-language productivity workflows
Language-heavy systems should prioritize context retrieval quality, concise output structure, and easy user correction loops.
Computer-vision and multimodal workflows
These implementations need strict test coverage across varied inputs. Edge-case behavior should be documented for support and onboarding teams.
Process automation workflows
Automation should always include human override where business risk is non-trivial. Reliability metrics matter more than feature count in early stages.
Use-case clarity improves both architecture decisions and page messaging because each audience can be guided by relevant proof.
No-Code vs Custom Build: Practical Decision Model
The best build path depends on validation stage, team capability, and risk profile. A binary "better vs worse" mindset usually leads to poor choices.
When no-code is often the right first move
- You need fast market validation with limited engineering bandwidth.
- Core value depends on workflow design more than deep infrastructure control.
- You want quick launch loops for message and onboarding experiments.
When custom development is usually justified
- You need strict control over model orchestration and data pipelines.
- Security and compliance constraints require deeper implementation control.
- Product differentiation relies on proprietary system behavior.
Hybrid path for many teams
A common winning path is hybrid execution: validate use cases and conversion flow quickly with no-code page and onboarding layers, then deepen custom infrastructure after fit signals are strong.
The right decision is the one that shortens time to reliable learning without creating unacceptable technical debt.
Tooling and Stack Decisions That Matter Early
Early stack decisions should be reversible where possible. Irreversible choices are expensive when product direction changes.
Prioritize these dimensions when selecting tools:
- integration reliability with your existing systems
- observability and logging clarity
- deployment speed and rollback safety
- total cost under realistic usage growth
- quality of documentation and support
Avoid over-optimizing for edge features before core workflow metrics stabilize.
For teams balancing frontend workflow quality and model iteration, this guide on AI in web development for beginners helps keep implementation decisions grounded in practical architecture.
Cost and Timeline Planning Without Guesswork
Most budget surprises come from hidden operational work rather than headline model costs. Teams estimate build effort and underestimate integration, testing, and support overhead.
A practical timeline model has four phases:
- discovery and scoping
- build and integration
- validation and pre-launch QA
- post-launch stabilization
Each phase should have one decision gate with explicit exit criteria. Without gate criteria, projects drift into "almost ready" mode for too long.
Cost planning should separate fixed setup costs from variable usage costs. This distinction is important when evaluating acquisition scale plans because conversion gains can increase model usage volume significantly.
UX, Personalization, and Conversational Flows
Personalization and conversational interfaces can improve clarity when implemented with discipline. They can also create noise if they are layered on top of unclear core messaging.
Start with low-risk personalization changes first, such as intent-based content ordering and role-specific examples. Expand only after measurable improvement appears.
Conversational components should guide decisions, not replace them. The best implementations help users qualify fit, clarify constraints, and choose next steps with confidence.
If you are expanding adaptive experiences, this practical overview of machine learning in web development is useful for sequencing personalization depth without losing UX coherence.
Guardrails for conversational and personalized UX
- keep response scope tied to verified product capabilities
- show confidence boundaries when certainty is limited
- keep a clear path to human support for complex edge cases
- measure quality outcomes, not only engagement volume
These rules reduce false confidence and protect long-term trust.
Trust Design for AI Product Pages
AI products carry additional credibility burden. Users need to know how the system behaves under uncertainty and what safeguards exist when output quality varies.
Place trust language near high-impact claims and high-commitment CTAs. If trust details are hidden in policy pages, users often decide before they see them.
High-value trust modules include:
- concise capability boundaries
- data handling summary in plain language
- human oversight and fallback path
- realistic examples with scope context
Trust modules should be updated as product behavior evolves. Outdated trust language damages credibility faster than missing trust language.
Conversion Architecture in Unicorn Platform
Achieving Effective Conversion
Unicorn Platform works best when page variants are aligned to intent stages instead of traffic channels alone. Visitors at different readiness levels need different depth and proof.
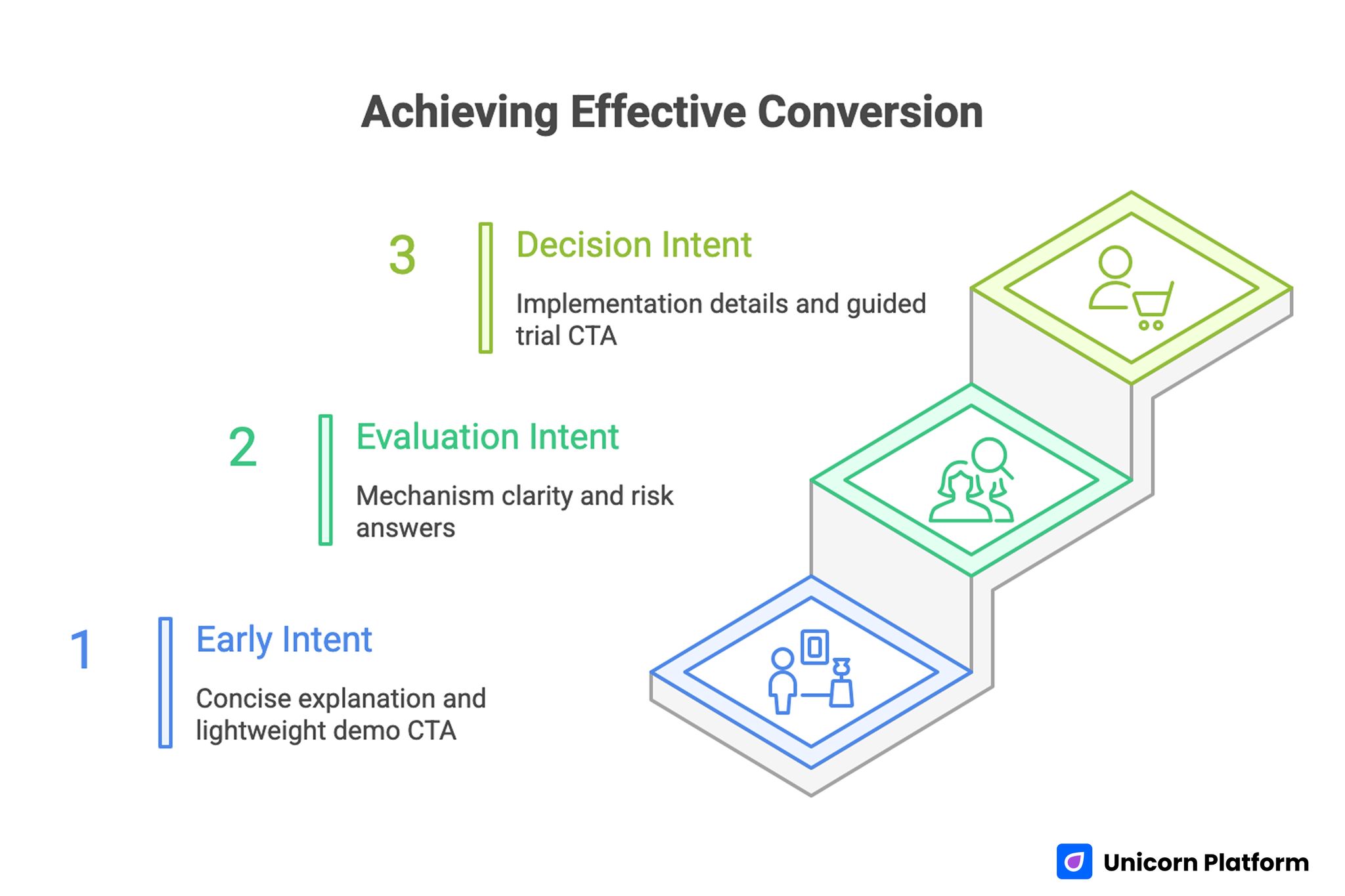
A practical three-stage conversion architecture:
- early intent: concise use-case explanation and lightweight demo CTA
- evaluation intent: mechanism clarity, comparisons, and risk answers
- decision intent: implementation details, proof, and guided trial CTA
For teams building launch pages around product workflow education, this AI landing page creation guide can help map section sequencing to user readiness.
Keep one primary CTA per page variant. Cleaner CTA hierarchy usually improves attribution quality and simplifies optimization decisions.
Data Readiness and Evaluation Before Scale
Model behavior is only as reliable as the data and evaluation process around it. Many teams move to launch while data quality is still unstable, then misdiagnose production issues as model issues.
Build a minimum evaluation layer before scaling traffic. Define benchmark tasks that represent real user intent, then measure output quality with clear pass and fail criteria. Use consistent datasets for comparison so iteration decisions remain meaningful.
Evaluation should include three quality lenses:
- task success quality: does the output solve the requested job?
- reliability quality: does quality hold across input variation?
- safety quality: does behavior stay within defined policy boundaries?
When these checks are visible in release notes, product, growth, and support teams can align around the same quality language. This reduces internal debate and speeds decision-making during fast iteration cycles.
Delivery Model for Cross-Functional Teams
Shipping AI products requires tighter coordination than traditional feature releases because product behavior, user trust, and messaging claims change together. A cross-functional delivery model prevents one team from moving ahead while another team lags.
Use a simple ownership map for every release:
- product owner defines user outcome and scope boundaries
- AI owner manages model behavior and evaluation thresholds
- UX owner validates first-value interaction clarity
- growth owner aligns page narrative and source-specific CTA
- QA owner verifies trust language, telemetry, and release checks
This model works well for small teams because roles can be shared while responsibilities stay explicit. Clarity in ownership reduces launch delays and makes post-launch debugging significantly faster.
30-Day Launch Plan
Week 1: problem and scope lock
Define one measurable user outcome, one success metric, and one high-confidence use case. Freeze non-essential features for the first release.
Week 2: product and page alignment
Build first-value onboarding path and align page message with actual product behavior. Add trust modules near feature claims and commitment points.
Week 3: controlled validation
Launch limited traffic and track comprehension, activation quality, and drop-off points. Run one meaningful experiment at a time.
Week 4: refine and scale baseline
Keep winning variants, remove noisy elements, and document learned constraints. Prepare next iteration based on observed behavior rather than assumptions.
This plan is intentionally focused. Narrow scope in month one produces better signal quality and faster iteration velocity.
90-Day Optimization Loop
Days 1-30: stabilize core narrative and activation
Improve first-screen clarity, onboarding guidance, and trust placement. Confirm that acquisition promise matches product reality.
Days 31-60: expand use-case coverage carefully
Add one adjacent use case and validate whether existing architecture supports it without harming baseline quality.
Days 61-90: scale what is proven
Extend proven patterns across additional segments, then formalize operating standards for experimentation, trust updates, and release QA.
This loop turns early launches into a compounding system instead of a sequence of disconnected experiments.
Common Failure Patterns and Fast Fixes
Failure pattern: high click-through, weak activation
Fix by tightening mechanism explanation and first-value onboarding steps. Users should understand output quality expectations before they commit.
Failure pattern: strong engagement, low qualified leads
Fix by improving qualification language and scope boundaries in both page copy and conversational flows.
Failure pattern: personalization increases complexity
Fix by reducing adaptive variables and keeping one stable narrative spine across all variants.
Failure pattern: trust concerns appear late
Fix by moving capability boundaries and data summary language closer to claims that create user risk perception.
Failure pattern: testing chaos
Fix by limiting concurrent experiments and documenting one hypothesis per release cycle.
Teams that review these patterns monthly usually improve faster because errors are corrected systemically, not one page at a time.
Documentation Standard for Repeatable Performance
Maintain short release notes for major updates. Each note should include hypothesis, audience segment, expected metric impact, and observed result window.
This habit keeps experimentation cumulative. New team members can understand why a page changed, and decision quality improves as historical context grows.
A lightweight documentation standard is one of the highest-leverage process improvements for growing AI product teams.
FAQ: Building AI Products in 2026
What is the best first step for a new AI product?
Define one measurable user outcome tied to a real workflow. Product quality improves faster when scope starts narrow and outcome-focused.
Should we prioritize model sophistication or UX clarity first?
UX clarity usually delivers earlier gains in adoption quality. Model depth matters, but users must first understand how to get value.
How long does a realistic first launch usually take?
Timeline depends on scope and integration complexity, but teams move faster when they define strict decision gates for each phase.
Is no-code viable for serious AI products?
It is viable for validation and early conversion workflow testing. Many teams then add custom depth after fit signals are strong.
How do we avoid overpromising in marketing copy?
Use capability boundaries, realistic examples, and plain-language trust modules near key claims.
What metrics matter most in early stages?
Comprehension quality, first-value completion, qualified conversion, and retention-adjacent signals are more useful than raw traffic volume.
How should conversational components be measured?
Track outcomes such as qualification accuracy, guided next-step completion, and support deflection quality rather than chat volume.
When should we add personalization?
Add it after baseline clarity is stable. Start with low-risk adjustments and expand only when quality metrics improve.
How do we align product and landing pages better?
Map one consistent narrative from first-screen promise to onboarding outcome. Misalignment at any stage reduces trust and adoption.
What is the biggest long-term mistake teams make?
Treating launch pages and product behavior as separate systems. Durable growth requires both layers to be designed and optimized together.
Final Takeaway
Building successful AI products in 2026 requires more than strong model output. It requires clear workflow design, trustworthy communication, disciplined experimentation, and conversion architecture that reflects real product behavior.
With Unicorn Platform, teams can move quickly without losing structure by aligning first-value UX, trust modules, and intent-based page variants in one operating system. That alignment is what turns early interest into durable adoption quality.