Table of Contents
- Why AI-Assisted Pages Still Underperform
- 30-Day Implementation Plan
- Common Failure Modes and Practical Fixes
- FAQ
AI has made it easy to produce draft pages quickly, but speed alone does not create business outcomes. Many teams publish more variants than ever and still see weak lead quality, inconsistent conversion behavior, and unclear test results.
The problem is usually not the technology. The problem is workflow design. When teams use AI to generate copy without strong message architecture, proof controls, and release discipline, output volume increases while decision quality declines.
High-performing teams treat AI-assisted production as a controlled operating system. AI expands options and reduces draft time. Humans define strategic direction, verify claims, align trust signals, and protect narrative clarity.
Unicorn Platform supports this model well because teams can iterate rapidly with reusable structures while maintaining ownership and QA gates. That combination is what turns fast publishing into compounding performance, not random experimentation.
sbb-itb-bf47c9b
Quick Takeaways
Enhancing Landing Page Conversion with AI
- AI should accelerate drafts, not replace message strategy.
- Stable section architecture improves both conversion and test clarity.
- First-screen relevance and mechanism clarity drive most performance gains.
- Trust cues must be specific, current, and adjacent to major claims.
- One dominant CTA per variant is usually the highest-conversion pattern.
- Mobile QA should be mandatory for every release cycle.
- Guardrail metrics are essential to protect downstream quality.
- Documentation and ownership turn speed into reliable growth.
Why AI-Assisted Pages Still Underperform
Underperformance often starts with generic language. AI-generated openers can sound polished but vague, especially when prompts do not include audience context, use-case constraints, or outcome specificity.
The second issue is proof mismatch. Pages make strong claims, but supporting evidence is delayed, weakly contextualized, or missing entirely. This increases hesitation at the exact moment confidence is needed.
The third issue is fragmented CTA logic. Teams publish multiple equal-priority actions because they want to serve every user stage at once. This usually creates uncertainty rather than flexibility.
The fourth issue is operational noise. Too many elements are changed in the same release cycle, making it impossible to identify what actually improved performance.
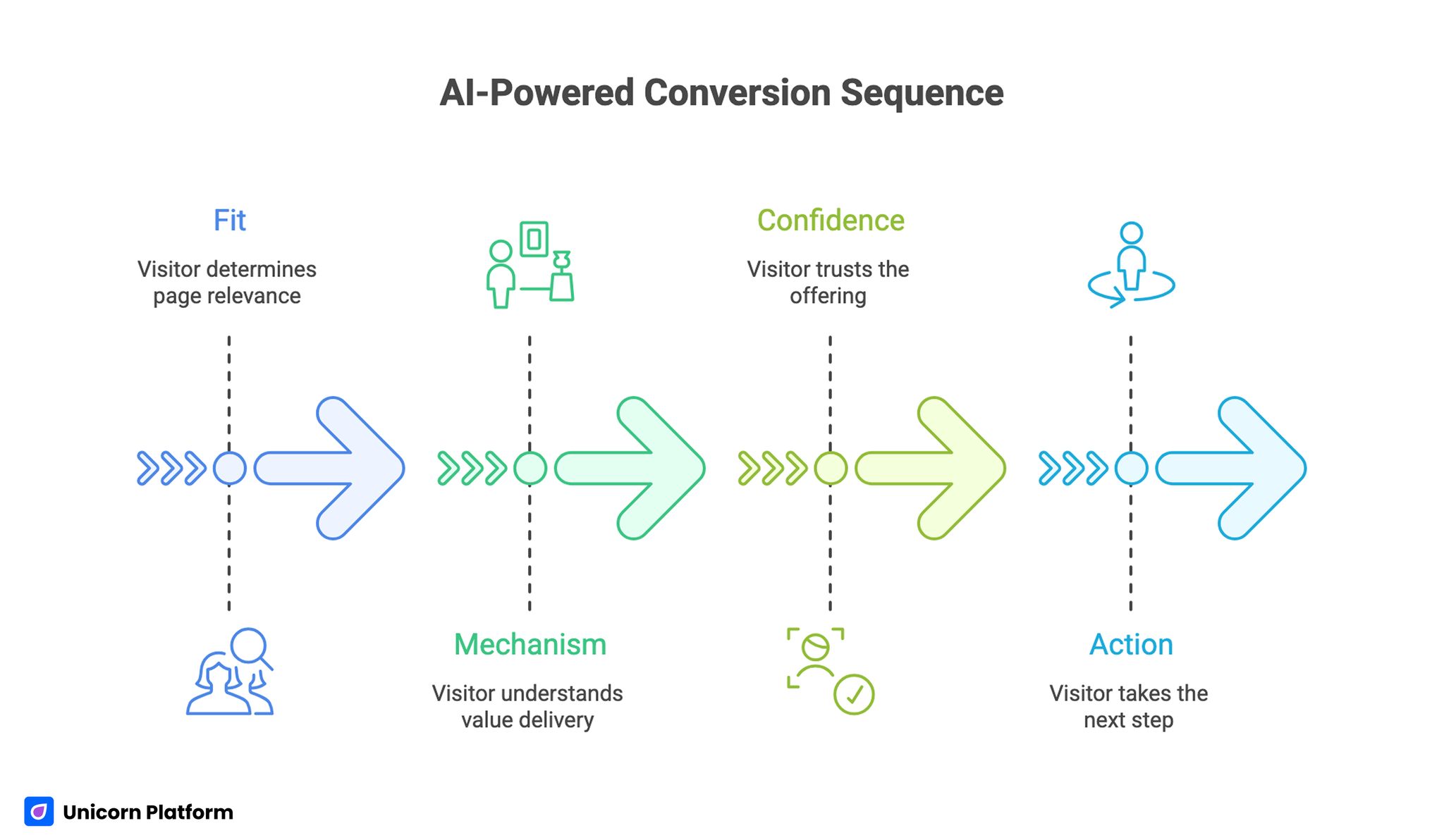
The Conversion Sequence for AI-Powered Workflows
AI-Powered Conversion Sequence
The strongest pages still follow a human decision sequence: fit, mechanism, confidence, and action.
Fit tells the visitor whether the page is relevant. Mechanism explains how value is delivered. Confidence reduces risk through evidence and transparency. Action provides a clear next step with limited friction.
AI can generate language for each stage, but teams should control the sequence manually. If this order breaks, conversion quality drops regardless of visual quality.
Teams refining sequence design can align with this high-converting section architecture guide when building reusable templates.
First-Screen Clarity for AI Offers
AI-related offers often trigger skepticism because users have seen exaggerated claims. First-screen copy should avoid hype and focus on concrete value.
A useful first-screen pattern includes four elements: audience context, practical outcome, delivery mechanism, and one primary action. This gives enough certainty for users to continue without forcing long-form reading.
First-screen edits usually produce the fastest measurable improvements. When teams shorten vague headlines and replace generic phrases with real workflow outcomes, both engagement and conversion quality rise.
First-Screen QA Questions
- Is the audience explicitly identified?
- Is the promised outcome concrete and believable?
- Is the action path clear in one glance?
- Is there an immediate reason to trust the claim?
If one answer is weak, revise before launching tests.
Mechanism Transparency: Show How the AI Actually Helps
Visitors convert faster when they understand where AI adds value and where human control remains. Hidden mechanism details create uncertainty, especially in B2B and higher-consideration offers.
A strong mechanism section should explain the workflow in simple steps: input, transformation, review, and output. It should also clarify constraints so users do not assume unrealistic capabilities.
Teams that describe mechanism clearly usually see better-qualified conversions because users enter with more accurate expectations.
Claim Validation and Proof Design
AI copy can produce strong claims quickly, but claims without evidence reduce trust. Proof should be tied directly to specific statements, not placed as isolated testimonials.
Useful proof types include quantified outcomes with timeframe, role-specific feedback, and implementation snapshots showing real workflow improvement.
Proof freshness matters. Outdated evidence can reduce credibility even when the page structure is strong. Teams should assign proof ownership and refresh cadence for active pages.
For teams integrating AI-assisted iterations into existing pages, this prompt-based change workflow guide can support safer revision cycles.
Prompt System Design for Better Draft Quality
Prompt quality determines output quality. Broad prompts usually produce broad copy. Structured prompts produce usable drafts faster.
A practical prompt template should include: target audience, specific problem, expected transformation, required proof style, prohibited claim types, CTA intent stage, and tone constraints.
Teams should maintain a small prompt library by page objective. Reusing proven prompt structures reduces variance and speeds editorial review.
Prompt Components That Matter Most
- audience and context definition
- offer boundaries and exclusions
- required section jobs
- claim validation requirements
- CTA intent alignment
- quality constraints and forbidden wording
These components reduce rework and improve consistency across contributors.
Human Editorial Layer: Non-Negotiable Controls
AI can draft quickly, but final publication requires human editorial control. The editor should verify factual accuracy, relevance, tone, and conversion logic.
Human review should also remove over-optimized phrasing, repeated claim patterns, and unsupported confidence statements.
The most effective teams define a strict release rule: no AI-generated line is published without editorial ownership of truth and usability.
No-Code Execution With Governance
No-code execution gives marketing and growth teams speed, but speed without governance creates quality drift.
A lightweight governance model should define who can change messaging, who can update proof, who can alter form logic, and who approves final release.
Unicorn Platform makes fast collaboration possible, but predictable outcomes come from role clarity and release discipline.
For teams generating many draft options, this AI page generator workflow can accelerate ideation when paired with strict approval rules.
CTA Strategy by Intent Stage
AI-focused pages often mix exploration and commitment CTAs in the same visual priority. This confuses users and weakens routing quality.
A better model is stage-specific hierarchy. Early-stage traffic gets one low-friction CTA. Mid-intent traffic gets one evaluation CTA. Decision-stage traffic gets one high-commitment CTA.
Each variant should still have one dominant action and one controlled fallback at most. This keeps decisions clear and improves attribution quality.
Form Design and Qualification Depth
Form strategy should preserve momentum while collecting enough context for routing quality. Over-collection at first touch can reduce completion without improving fit.
A strong first-step form usually includes only essential contact fields and one intent qualifier. Deeper qualification can happen after initial conversion.
Teams should evaluate each field against one question: does this field change what happens next. If not, defer it.
Qualification Progression Model
- step one: minimal conversion capture
- step two: intent and readiness context
- step three: personalized routing or scheduling
This model protects volume while improving downstream conversation quality.
Mobile-First QA for AI Page Programs
A large share of AI-related campaign traffic comes from mobile channels. If copy, CTA, or form flow is weak on smaller screens, conversion quality drops before users reach deeper sections.
Mobile QA should include first-screen readability, CTA tap comfort, keyboard behavior, form validation clarity, and confirmation continuity.
Real-device testing is mandatory before scaling traffic. Desktop-only review misses many high-impact friction points.
Channel-Aware Variants With Stable Architecture
Search users, social users, email users, and retargeting users arrive with different context. One static version usually underperforms across all sources.
The best approach is one stable structural template with controlled message adaptations by source intent. Adjust headline framing, proof order, and CTA wording while keeping section order consistent.
This method improves relevance and keeps test interpretation clean because structural variables remain fixed.
Measurement Framework for AI Campaign Reliability
Top-line conversion rates are useful but insufficient. Teams need layered metrics to avoid optimizing one stage while degrading another.
Layer one tracks page actions: clicks, starts, submissions. Layer two tracks quality signals: qualified intent, follow-up engagement, acceptance rates. Layer three tracks business outcomes: opportunity progression, activation quality, and revenue contribution.
Every test should include one primary metric and one guardrail metric. Guardrails prevent false wins driven by low-intent volume.
Practical Metric Pairing
- top-funnel campaign: primary is qualified submissions, guardrail is low-fit rate
- trial campaign: primary is trial starts, guardrail is activation completion
- sales campaign: primary is qualified meeting conversion, guardrail is no-show trend
This discipline improves forecasting and protects downstream efficiency.
Weekly Optimization Cadence

Weekly Optimization Cadence for Cadence for AI-Driven Landing Page
A weekly cadence supports consistent learning. Random edits under deadline pressure usually increase noise and reduce insight quality.
A practical cycle: Monday diagnostics, Tuesday hypothesis selection, Wednesday implementation, Thursday QA verification, Friday rollout decision.
One major variable per cycle is enough for clean interpretation. Teams that follow this rhythm typically improve faster than teams running frequent multi-variable changes.
Monthly Freshness and Risk Controls
AI offer pages decay when claims, examples, or trust signals become outdated. Monthly freshness reviews keep credibility aligned with current reality.
A monthly review should validate proof recency, claim accuracy, CTA relevance, and form behavior. Quarterly reviews should evaluate template-level performance and retire weak modules.
Risk controls should include alerting for conversion anomalies, integration failures, and significant guardrail deterioration. Clear recovery playbooks reduce decision latency during performance drops.
Advanced Experimentation: From A/B to Program Learning
Once baseline structure is stable, teams should shift from isolated tests to program-level learning. This means tracking patterns across experiments, not only individual winner/loser outcomes.
Program learning helps answer deeper questions: which claim types perform best by audience stage, which proof formats build confidence fastest, and which CTA routes produce the strongest downstream quality.
Teams should maintain a shared decision log for all major tests. Logs should include hypothesis, change scope, result interpretation, and whether the change was promoted, reverted, or retested.
This practice prevents repeated low-value experiments and strengthens strategic planning.
Governance for Multi-Owner Teams
As teams scale, more contributors touch page systems. Without governance, speed becomes inconsistency.
A practical governance model includes four owners: messaging owner, proof owner, performance owner, and QA owner. Each owner has explicit responsibilities and escalation paths.
High-impact changes should require structured approval before launch. This includes structural changes, integration changes, and claim-level updates affecting trust.
Release Gate Checklist
- message clarity and fit validation
- claim-proof alignment check
- CTA and form routing check
- mobile interaction check
- metric instrumentation check
If one gate fails, launch should pause until resolved.
Scenario: Startup Team Improving Qualified Leads
A startup used AI-assisted drafts to accelerate campaign launches. Output volume improved, but qualified lead quality remained weak.
Audit revealed three issues: generic first-screen messaging, proof disconnected from core claims, and mixed CTA intent in one variant.
The team rebuilt on Unicorn Platform with stable sequence design, stronger mechanism clarity, and one dominant CTA per source-specific version.
After eight weeks, qualified lead rate improved and low-fit submissions declined. The biggest gains came from clarity and trust alignment, not from additional design complexity.
Scenario: Agency Standardizing AI Workflows
An agency managing multiple client campaigns struggled with inconsistent results from rapid AI drafting.
They implemented a shared prompt library, human editorial approval rules, and release gates tied to quality metrics.
They also moved to source-aware variants with stable architecture and weekly single-variable testing.
Within one quarter, campaign predictability improved and rework decreased because successful modules were promoted into a shared template library.
30-Day Implementation Plan
Week 1: Baseline and Structure Lock
Audit one high-priority page against fit, mechanism, confidence, and action sequence. Identify the highest-leak section.
Define one primary metric and one guardrail metric. Lock the base structure and remove conflicting CTA routes.
Week 2: Messaging and Proof Rebuild
Rewrite first-screen copy for audience clarity and concrete outcome. Reposition proof near major claims.
Validate mechanism transparency and remove unsupported statements.
Week 3: Variant Launch and QA
Launch one channel-specific variant with one major message change. Keep structure fixed.
Run full mobile QA and confirm measurement instrumentation before scaling.
Week 4: Consolidation and Documentation
Promote validated sections into the base template. Archive weak variants and update decision logs.
Schedule monthly freshness ownership and next-cycle hypothesis planning.
90-Day Scale Plan
Month 2: Expand by Intent Segment
Build controlled variants for cold, warm, and high-intent audiences using the same structural backbone.
Create reusable modules for hero framing, mechanism blocks, proof types, and CTA pathways.
Month 3: Operationalize Reliability
Formalize release gates, ownership rules, and rollback triggers tied to guardrail decline.
Require decision logs for all major changes so learning compounds across teams and campaigns.
At this stage, scale should come from repeatable system quality, not from constant redesign.
Common Failure Modes and Practical Fixes
1) Generic AI Promise
Visitors cannot tell who the offer helps or what changes. Replace broad claims with role-specific outcome language so relevance is obvious in the first screen.
2) Mechanism Ambiguity
Users do not understand how AI contributes to the workflow. Add concise process explanation and boundaries so users can evaluate effort and trust faster.
3) Unsupported Claims
Strong statements appear without proof. Pair each major claim with contextual evidence that includes role, timeframe, or measurable impact.
4) CTA Intent Conflicts
Multiple equal CTAs confuse readiness paths. Use one dominant route and one fallback option so user intent signals remain clean.
5) Over-Qualified First Forms
Excessive fields reduce completion quality. Use staged qualification and defer low-value inputs until intent is confirmed.
6) Mobile Friction Ignored
Desktop checks hide phone interaction problems. Require real-device QA before launch, including slower-network and keyboard behavior validation.
7) Source Mismatch
One message serves all channels and underperforms. Use source-aware framing with stable structure so experiments remain interpretable.
8) Weak Confirmation Continuity
Users convert but lose momentum after submit. Add immediate clarity on next steps and expectations to preserve intent after conversion.
9) Volume-Only Reporting
Top-line conversions rise while quality declines. Track layered metrics with guardrails so downstream quality stays visible.
10) No Ownership Model
Fast edits create drift and rework. Define owners and enforce release checks so accountability remains explicit under pressure.
Pre-Launch QA Checklist
Confirm first-screen fit clarity, mechanism transparency, and one dominant action path. Verify proof appears near major claims.
Check form behavior, CTA routing, and confirmation continuity on real mobile devices.
Validate primary and guardrail instrumentation before scaling. Require final QA sign-off.
FAQ: AI-Driven Landing Page Workflows
Does AI make landing page teams obsolete?
No. AI accelerates drafting, but strategy, truth validation, and conversion design still require human ownership. Teams that remove editorial control usually publish faster but convert less reliably.
What should teams optimize first?
Start with first-screen clarity and claim-proof alignment. These usually drive the fastest quality gains because they shape trust before form interaction.
Should teams run many variants at once?
Only if governance is strong. Most teams learn faster with controlled single-variable tests and clear success criteria.
How much mechanism detail is enough?
Provide enough clarity for users to trust the process without overloading them with technical depth. The best benchmark is whether users can explain the workflow after one quick read.
What is the biggest AI page mistake?
Publishing generic or unsupported claims that sound polished but fail trust checks. These claims often increase clicks while reducing qualified conversion later in the funnel.
How often should proof be refreshed?
Monthly for active campaigns and quarterly at template level. High-change offers may require faster refresh cycles during launch windows.
Can no-code speed hurt performance?
Yes, if teams skip release gates and ownership rules. Speed should increase learning velocity, not remove quality controls.
Which metric matters most?
The primary metric depends on campaign objective, but it must be paired with a quality guardrail. Without guardrails, short-term wins can hide long-term performance decline.
How should teams handle performance drops?
Use predefined rollback criteria, isolate the last major change, and retest with controlled scope. Fast diagnosis is easier when changes are logged and released in small increments.
What creates compounding gains in AI page programs?
Stable architecture, disciplined experimentation, clear ownership, and reusable learning logs. Compounding outcomes come from operational consistency rather than constant redesign.
Final Takeaway
AI-assisted production can improve speed dramatically, but sustainable performance comes from structure, proof discipline, and operational clarity.
Unicorn Platform gives teams the environment to run this model well. Keep the narrative stable, test one major variable at a time, and optimize for downstream quality, not just top-line activity.