Table of Contents
- The Core Structure That Keeps AI Pages Reliable
- A Practical 10-Step Production Workflow
- 30-Day Implementation Plan
- Common Failure Patterns and Fast Fixes
- FAQ
AI changed website production speed faster than most teams expected. What used to take days of drafting and iteration can now happen in a single session. The operational risk is that velocity can rise while decision quality drops.
Fast output is easy. Reliable outcomes are harder. High-performing teams are not simply using more AI prompts. They are running a clearer system for structure, proof, release checks, and post-launch learning.
No-code environments make this gap visible. When publishing bottlenecks disappear, weaknesses in message clarity and governance become the main performance limit.
Unicorn Platform works best when AI is treated as a production amplifier inside a disciplined workflow. This article explains how to build that workflow step by step.
sbb-itb-bf47c9b
Quick Takeaways
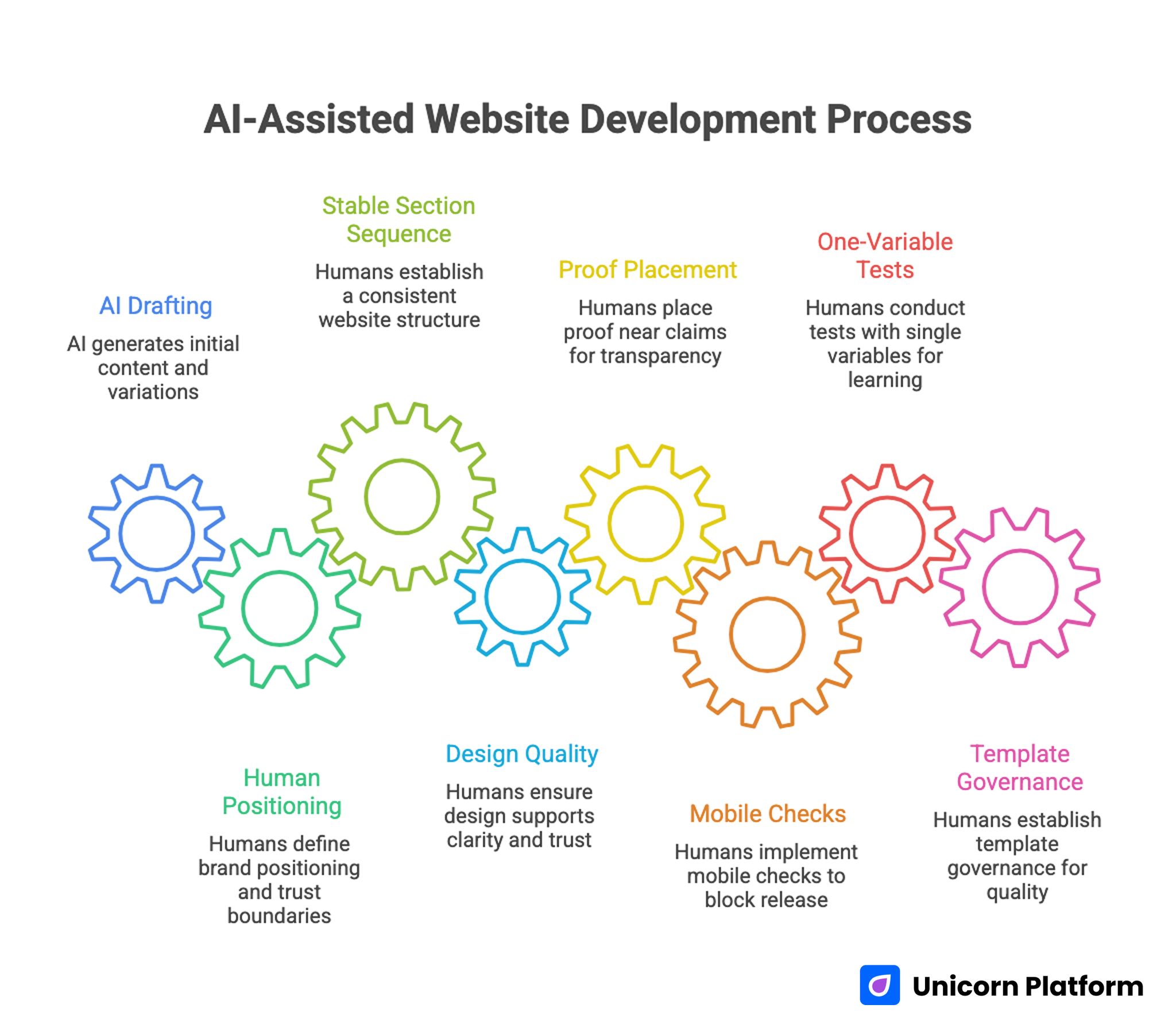
AI-Assisted Website Development Process
- AI is strongest in drafting, variation, and repetitive production tasks.
- Humans should still own positioning, trust boundaries, and final release decisions.
- A stable section sequence is the fastest way to prevent conversion drift.
- Design quality should support decision clarity, not visual novelty.
- Proof must sit near claims, especially before high-friction actions.
- Mobile checks should block release when key criteria fail.
- One-variable tests produce cleaner learning than frequent mixed edits.
- Template governance is what keeps quality stable at scale.
Why AI-Generated Pages Often Feel Complete but Underperform
Many AI-generated pages look polished on first review and still underperform in real traffic. The most common issue is generic relevance. Users can read the page and still wonder if it is actually for them.
A second issue is shallow mechanism explanation. Pages mention automation or intelligence but do not explain how the outcome is delivered in practical terms.
A third issue is trust timing. Proof content appears, but not where uncertainty is highest. Users encounter bold claims early and supporting evidence too late.
A fourth issue is uncontrolled iteration. Teams change headline, layout, and CTA logic at once, then cannot tell what caused the result.
Start With One Objective and One Audience Segment
Before opening any builder or prompt workflow, define one primary objective for the page. This objective can be a demo request, consultation booking, trial start, sign-up, or another measurable action.
Then define one primary audience segment with practical specificity. Role, use case, urgency, and context should all be clear enough to guide copy decisions.
This short planning step prevents most random edits later. It also improves AI prompt quality because the model gets focused context rather than vague direction.
Teams that want a simple launch path from brief to first draft can use how to create AI landing pages as a baseline workflow. It helps teams standardize the handoff from ideation to publish-ready content.
The Core Structure That Keeps AI Pages Reliable
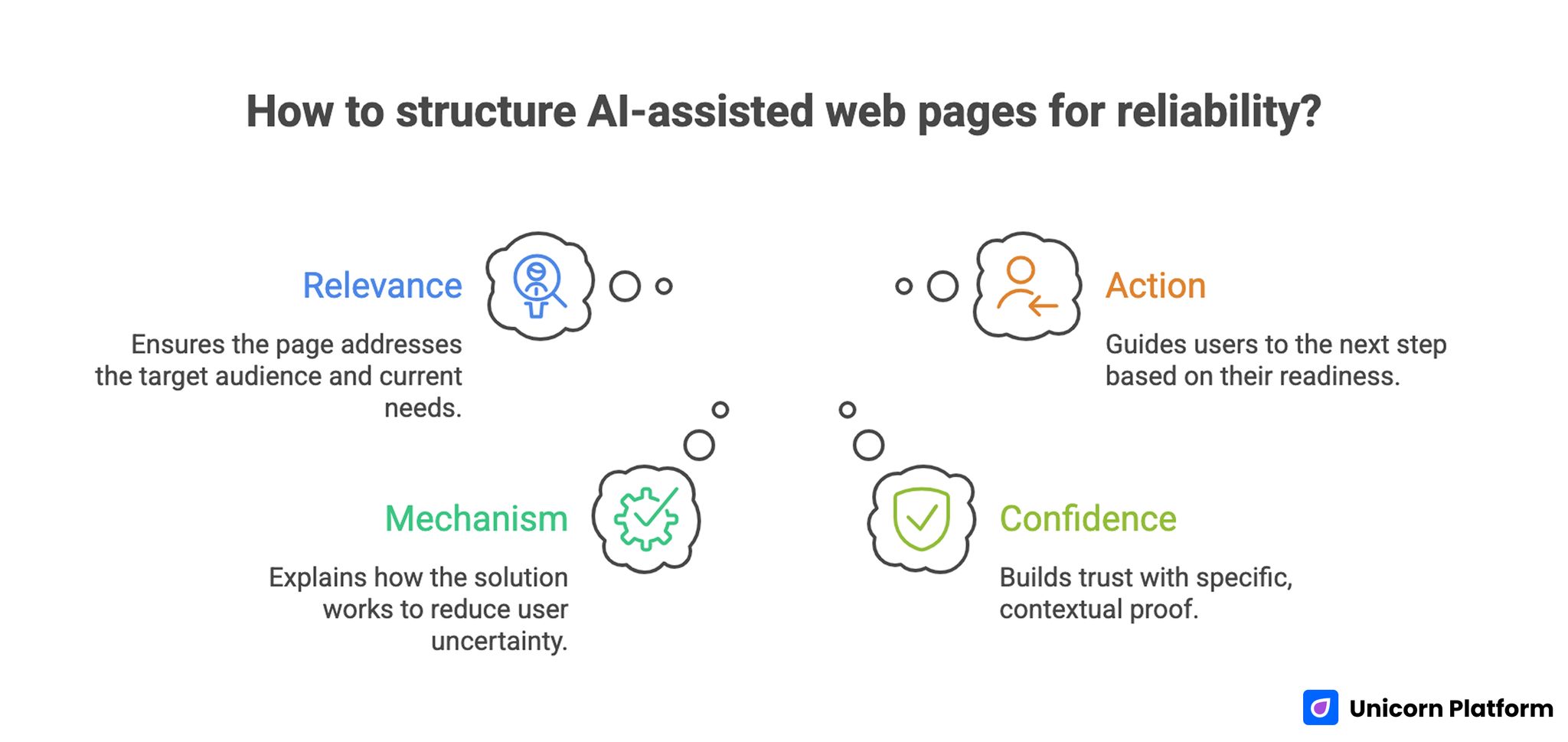
Core Structure of Reliable AI-Assisted Web Pages
Teams can test many creative directions while keeping one narrative spine stable. This spine should answer four user questions in sequence.
1. Relevance
Who is this page for, and why does it matter now? Relevance should be explicit in the first scan.
2. Mechanism
How does the solution work in practical terms? Mechanism should reduce uncertainty, not increase it.
3. Confidence
Why should users trust the claim? Confidence content should include specific, contextual proof.
4. Action
What should users do next? Action should match readiness level and expected effort.
This sequence is reusable across campaign types and traffic sources. If your team needs a deeper template for section ordering, a step-by-step guide to a high-converting landing page structure is a strong reference.
AI + Human Capability Allocation Model
Performance improves fastest when teams define ownership clearly instead of debating whether AI is replacing roles. Clear accountability turns experimentation into a reliable production rhythm.
AI-assisted tasks usually include draft generation, section variation, rewrite options, formatting cleanup, and summary generation from notes. These tasks benefit most from automation because they are repetitive and high-volume.
Human-led tasks should include positioning choices, claim validation, trust boundaries, release approval, and interpretation of test outcomes. These decisions carry business risk, so human ownership should remain explicit.
Joint-review tasks include mechanism depth, objection handling, CTA logic, and form friction design. These areas benefit from AI speed but still require editorial judgment.
This model protects both speed and accountability. Without it, teams drift between over-automation and manual bottlenecks.
A Practical 10-Step Production Workflow
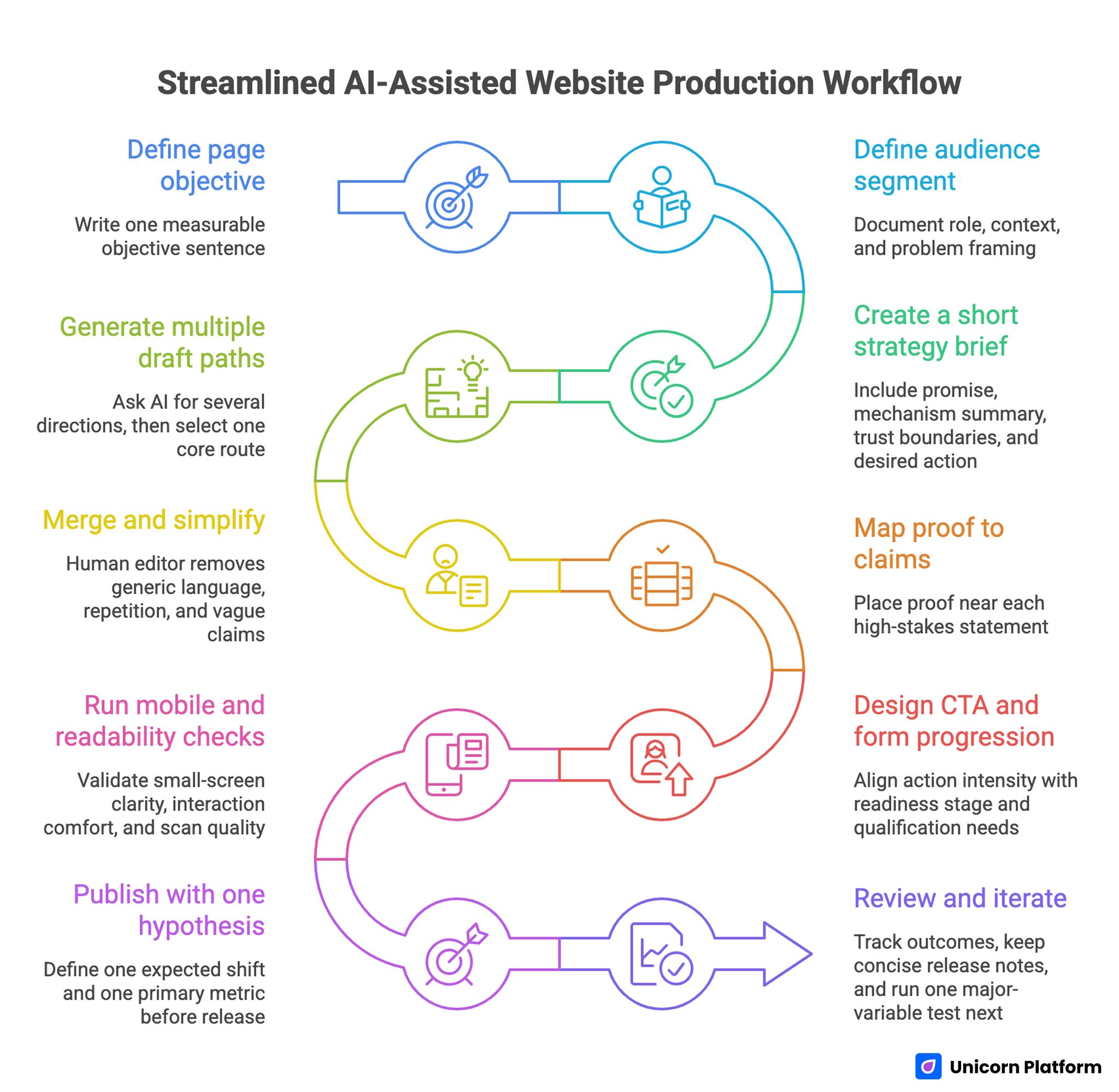
Streamline AI-Assisted Website Production Workflow
The workflow below is built for teams shipping frequently with no-code tools and AI assistance. Each step is meant to reduce a specific quality failure mode.
Step 1: Define page objective
Write one objective sentence that can be measured after launch. Objective clarity improves later testing discipline.
Step 2: Define audience segment
Document role, context, and problem framing in plain language. Keep it specific enough to guide message choices.
Step 3: Create a short strategy brief
Include promise, mechanism summary, trust boundaries, and desired action. This brief becomes the source of truth for both AI and human contributors.
Step 4: Generate multiple draft paths
Ask AI for several directions, then select one core route quickly. Excessive branching at this stage usually slows quality improvement.
Step 5: Merge and simplify
Human editor removes generic language, repetition, and vague claims. This curation step usually has the highest impact on final quality.
Step 6: Map proof to claims
Place proof near each high-stakes statement, not in a single isolated section. Claim-proof distance should stay short throughout the page.
Step 7: Design CTA and form progression
Align action intensity with readiness stage and qualification needs. Early CTAs should invite progress without creating confusion.
Step 8: Run mobile and readability checks
Validate small-screen clarity, interaction comfort, and scan quality. Mobile behavior should be treated as a strict release requirement.
Step 9: Publish with one hypothesis
Define one expected shift and one primary metric before release. This gives the team a clear basis for post-launch decisions.
Step 10: Review and iterate
Track outcomes, keep concise release notes, and run one major-variable test next. Consistent notes help teams avoid repeated mistakes.
This workflow keeps teams fast without sacrificing interpretability. It also improves onboarding because new contributors can follow the same sequence.
Design Systems for AI-Assisted Web Production
AI can suggest many visual directions quickly, but design quality still depends on system discipline. Teams need a compact style framework before scaling variants.
Define heading scale, spacing rhythm, button hierarchy, and component behavior for each page family. This prevents visual drift across contributors.
Use AI to explore alternatives inside those constraints. Constraint-based creativity usually produces stronger and more consistent outcomes than open-ended experimentation.
Visual emphasis should mirror decision priority. The most important value statement should dominate first-screen attention, followed by mechanism and trust cues.
Teams exploring visual refinement within no-code workflows can align this process with build beautiful websites without coding to keep design choices tied to conversion goals. Design adjustments should always map back to user decision quality.
Trust Architecture for AI-Era Pages
AI-assisted pages can trigger skepticism when claims sound broad or inflated. Trust strategy should be explicit and operational.
A useful rule is claim-proof proximity. If you state a speed benefit, show process evidence nearby. If you state an outcomes benefit, show context-rich proof near that claim.
Trust also includes boundaries. Transparent statements about scope and limitations improve lead quality because users self-qualify earlier.
Proof freshness should be reviewed on a recurring cadence. Stale testimonials, outdated screenshots, or obsolete examples reduce credibility even when layout quality is high.
CTA and Form Strategy for Better Fit
AI can improve top-of-funnel relevance and increase interaction volume. That is useful only when lead quality remains strong.
Action labels should describe actual next steps. Generic verbs create mismatch between user expectation and follow-up process.
Form strategy should reflect business context. High-ticket or consultative flows usually need early qualification cues. Lower-friction offers can qualify in later steps.
Every form field should have a clear operational purpose. If a field does not improve routing, qualification, or response relevance, remove it.
Teams that want structured test ideas for action and behavior optimization can use 10 user behavior tips to optimize landing pages to prioritize experiments. The best tests usually improve clarity before they improve aesthetics.
Mobile and Performance Release Gates
Desktop review is not enough for AI-produced pages. Mobile usually represents first contact, so clarity and interaction quality need explicit gating.
A practical mobile gate should confirm first-screen relevance, proof visibility before deep scroll, comfortable tap targets, and stable form behavior with keyboard interactions. These checks catch most high-impact friction before traffic is scaled.
Performance checks should focus on decision moments, especially around CTA and form areas. Small delays at these points often cause disproportionate conversion loss.
Release criteria should be binary for critical checks. If a core gate fails, publication should pause until the issue is resolved.
When teams need stronger small-screen execution patterns, creating a high-converting mobile app landing page offers practical implementation depth. It is useful for aligning layout choices with mobile intent behavior.
Measurement Model That Supports Real Learning
High-velocity production creates abundant data and frequent noise. Teams need a layered model to link edits to business impact.
Use four layers for review:
- clarity layer: engagement with first-screen and mechanism blocks
- interaction layer: progression through trust and action sections
- conversion layer: qualified submissions or bookings
- business layer: downstream pipeline and revenue signals
Each release should define one primary metric plus one guardrail. Guardrails reduce false wins, such as more submissions with weaker quality.
Weekly review cadence works for active programs. Monthly strategic reviews are useful for pattern-level decisions across page families.
Governance and Team Roles
As contributor count rises, no-code quality usually declines unless ownership is explicit. Clear role boundaries are essential.
A practical role map includes structure owner, trust owner, analytics owner, and release owner. In smaller teams, one person can hold multiple roles, but responsibilities should stay distinct.
Release notes should be lightweight but consistent. Record what changed, why it changed, expected impact, and observed impact.
Teams building stronger production governance can use build your custom website without coding as a companion framework for ownership and QA discipline. Governance quality is usually what separates short-term wins from durable growth.
Prompting Standards for Better AI Draft Quality
AI output quality depends heavily on input quality. Teams that write structured prompts get more usable drafts and spend less time on cleanup.
A strong prompt should include the page objective, audience segment, offer mechanism, trust boundaries, preferred section order, and CTA intent stage. Without these constraints, models usually generate fluent but generic content.
Prompting should also define exclusions. For example, disallow unverifiable claims, vague superlatives, and unsupported outcome statements. Clear exclusions reduce editing time and legal risk.
Teams should keep a prompt library by page type. Reusing validated prompt structures improves consistency across contributors and accelerates onboarding.
Prompt reviews should happen periodically, just like template reviews. As products and audiences change, prompt assumptions also need updates.
30-Day Implementation Plan
Week 1: Foundation and alignment
Define audience and objective for top pages, lock one narrative spine, and standardize first-screen relevance rules. This week should establish shared language across the team.
Week 2: Trust and action quality
Map claims to proof, tighten CTA wording, and remove nonessential form fields that do not improve routing or qualification. Keep the review scope focused so implementation stays fast.
Week 3: Controlled testing
Run one major-variable test per page family. Review both conversion rate and qualification impact.
Week 4: Standardization and rollout
Retire weak modules, scale winning blocks, and document patterns in a short internal operating note. This prevents performance gains from being lost in future edits.
This month should improve both output quality and interpretation confidence. It should also reduce debate around subjective page changes.
90-Day Operating Model
Month 1: Stabilize
Focus on structure consistency, proof quality, and release gate discipline. Avoid adding new complexity before this layer is stable.
Month 2: Optimize
Test mechanism clarity, trust placement, and CTA specificity with controlled hypotheses. Keep each test narrow enough to support clear attribution.
Month 3: Scale
Expand validated modules to adjacent campaigns and onboard contributors with documented standards. Standardization is what makes scale sustainable.
At day 90, success should look like repeatable qualified outcomes, not isolated spikes. Consistency is a better indicator than occasional peaks.
Common Failure Patterns and Fast Fixes
Failure pattern 1: polished pages with vague messaging
Cause is usually weak strategic input. AI draft quality depends heavily on brief quality.
Fix by clarifying audience, problem context, and promise boundaries before generation. Better briefs almost always improve first-draft quality.
Failure pattern 2: higher conversions but weaker lead fit
Cause is often broad CTA expectations and minimal qualification cues. This pattern usually increases low-fit submissions.
Fix by tightening action language and adding one routing-critical question early. Qualification quality improves when expectations are explicit.
Failure pattern 3: rapid updates with unclear learnings
Cause is multi-variable changes in the same release. Attribution quality drops when too many elements move together.
Fix by limiting each cycle to one major variable and maintaining concise test notes. This creates clearer learning loops.
Failure pattern 4: trust decline after scaling AI workflows
Cause is stale proof assets and unbounded claims. Users notice these inconsistencies quickly.
Fix by refreshing proof on schedule and adding explicit scope statements. Trust quality rises when boundaries are visible.
Failure pattern 5: quality drift across contributors
Cause is missing ownership and inconsistent template use. Teams then ship contradictory edits.
Fix by assigning clear decision rights and enforcing shared release gates. Simple governance usually outperforms complex review bureaucracy.
FAQ: Building AI-Assisted Websites
Can AI build a high-performing website without human help?
AI can generate strong drafts, but high-performing outcomes still require human decisions in strategy, trust, and release approval. The best teams blend AI throughput with strong editorial discipline.
What should teams automate first?
Start with repetitive drafting and transformation work, then expand as review quality improves. This lowers risk while building team confidence.
How many variants should we launch at once?
Launch only the number you can review and interpret properly. Too many variants usually reduce learning quality.
What is the most important section to fix first?
First-screen relevance is typically the highest-leverage improvement because it affects every downstream interaction. Clarity gains here often improve all later metrics.
How often should trust modules be refreshed?
Monthly is a solid baseline. High-volume programs may need more frequent updates.
Should every traffic source have a separate page?
Only when intent differences are meaningful enough to justify message changes. Extra variants without a clear reason usually reduce focus.
What metric should we prioritize first?
Choose one primary metric tied to qualified outcomes and protect it with a guardrail metric. This prevents false positives during optimization.
How do we reduce keyword-heavy AI writing?
Use clear editorial constraints and run a strict post-edit pass for natural phrasing. AI fluency should never replace manual quality review.
Do no-code teams still need engineering support?
For many launches, less engineering is needed than before, but technical oversight remains important for integrations and reliability. Scale usually exposes technical risks that drafts cannot reveal.
What makes AI-assisted teams durable over time?
Clear ownership, stable structure, strict QA, and disciplined measurement loops create lasting performance. These fundamentals keep AI speed useful over the long term.
Final Takeaway
AI-assisted website production is not a shortcut to automatic performance. It is a multiplier for teams with clear systems. In no-code environments, that system must include structure discipline, trust design, release gates, and measurable iteration.
With Unicorn Platform, teams can ship quickly and still protect outcome quality when AI speed is paired with human judgment and governance. That combination is what turns fast launches into sustainable growth
