Table of Contents
- Why AI Editing Changed the Economics of Landing Pages
- Three Platform Archetypes and When They Work Best
- A 30-Day Implementation Blueprint
- Common Failure Modes and Practical Fixes
- FAQ
AI now removes most of the mechanical friction from page editing. You no longer need a full handoff chain to test a headline angle, tighten a value proposition, or reshape a CTA block. The operational bottleneck has shifted from production speed to decision quality.
That change is easy to underestimate. Faster editing can either compound performance or compound mistakes, depending on how teams define scope, review language, and validate outcomes. When update volume rises without stronger guardrails, pages often become noisier, not better.
The teams that win with AI treat it like a structured optimization layer, not a replacement for strategy. They keep message architecture stable, run focused test cycles, and use clear release gates before each publish event. This approach preserves trust while still delivering the iteration speed modern growth programs need.
sbb-itb-bf47c9b
Quick Takeaways

AI Editing Best Practices
- AI editing improves results when it accelerates a defined workflow, not random copy generation.
- Tool choice should prioritize governance, integration depth, and mobile reliability over flashy output demos.
- Most high-value gains come from first-screen clarity, trust sequencing, and CTA precision.
- One major variable per release cycle keeps attribution clean and learning reusable.
- Human review should own positioning, claims, and promise integrity on every variant.
- A shared prompt library is useful only when paired with a shared QA library.
- Mobile and form behavior must act as release gates, not post-launch cleanup tasks.
- Teams should evaluate success by conversion quality and downstream progression, not submission volume alone.
Why AI Editing Changed the Economics of Landing Pages
Traditional optimization programs were constrained by time and staffing. Teams knew what to test, but each change required queueing design, copy, implementation, and QA. AI-assisted workflows reduce that cycle dramatically, which means organizations can test more hypotheses per month without expanding headcount.
The upside is obvious: faster launch velocity, shorter feedback loops, and better adaptation to campaign changes. The hidden risk is that speed exposes weak operating discipline. If the team cannot define which section is underperforming and why, AI simply produces more variation around an unclear problem statement.
A reliable program starts from one principle: velocity is only useful when it increases signal quality. If each new version introduces multiple uncontrolled edits, you get movement in metrics without trustworthy insight. That is how teams become busy while learning very little.
The Real Goal: Better Decisions, Not More Drafts
Many organizations adopt AI tools expecting that better copy will emerge automatically. In practice, most performance gains come from better decisions about structure, sequence, and intent alignment. The draft itself matters, but decision discipline matters more.
A high-performing page usually answers four questions in order: who this is for, what outcome is possible, why the claim is credible, and what to do next. If AI-generated edits weaken one of those answers, conversion quality can fall even when language looks polished.
Editorial systems should therefore separate creative generation from publish authority. AI can produce options quickly, but final release should still require human validation of relevance, factual safety, and action clarity. This separation keeps execution fast while protecting message coherence.
Tool Selection Framework: How to Choose the Right Platform
Selecting a builder for AI-driven page updates should not start with templates. It should start with operating requirements. A strong platform is one your team can trust across repeated campaigns, not one that looks impressive in a single demo.
Evaluate candidates across seven dimensions. These criteria keep evaluation focused on operating fit instead of surface-level demos.
- Workflow speed: Can teams draft, edit, preview, and publish quickly without engineering support?
- Governance controls: Are roles, approvals, and reusable components enforced at the platform level?
- Variant management: Can you manage multiple hypotheses without losing version history?
- Integration depth: Does form and behavior data flow cleanly into your CRM and analytics stack?
- Mobile reliability: Are responsive behavior and interaction stability predictable across devices?
- Performance baseline: Do generated pages stay lightweight under realistic content loads?
- Team usability: Can non-technical contributors make safe edits without breaking architecture?
The strongest buying decision usually comes from weighted scoring. Instead of asking which tool is "best" in general, define what matters most for your motion, then score each option against that model. A startup running rapid acquisition campaigns will weight speed and flexibility differently than an enterprise team that needs strict compliance controls.
Three Platform Archetypes and When They Work Best
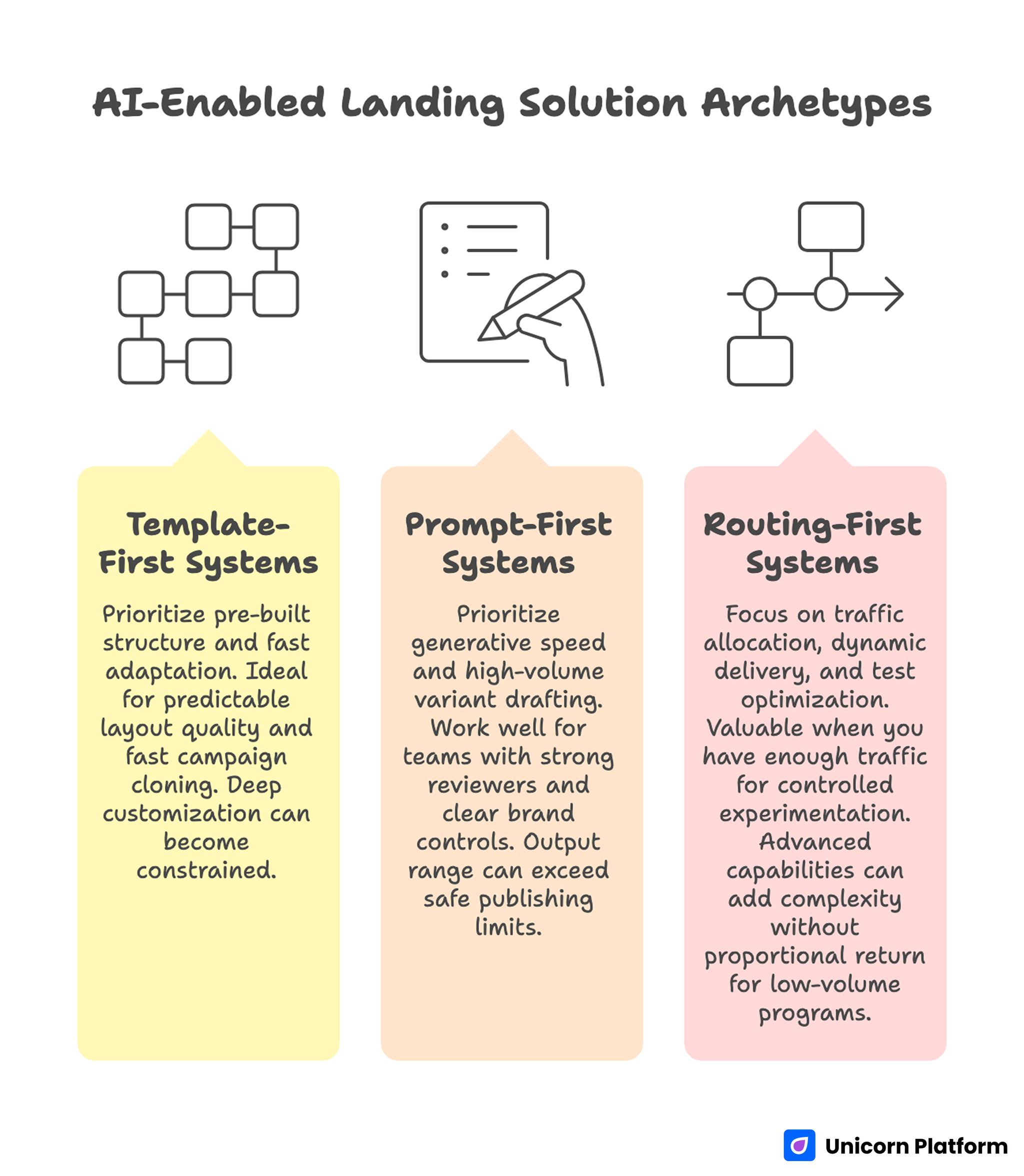
AI-Enabled Landing Solution Archetypes
Most AI-enabled landing solutions fit one of three operating styles. Understanding the style helps you avoid workflow mismatch after adoption.
1. Template-first systems
These platforms prioritize pre-built structure and fast adaptation. They are ideal when teams need predictable layout quality and fast campaign cloning. The tradeoff is that deep customization can become constrained once you push beyond default section logic.
2. Prompt-first systems
Prompt-first products prioritize generative speed and high-volume variant drafting. They work well for teams that already have strong reviewers and clear brand controls. Without those controls, the output range can exceed what is safe to publish.
3. Routing-first systems
Routing-first tools focus on traffic allocation, dynamic delivery, and test optimization. They become valuable when you already have enough traffic to support controlled experimentation at scale. For low-volume programs, these advanced capabilities can add complexity without proportional return.
Most mature teams combine styles over time. They begin with template stability, add prompt workflows for section-level iteration, then layer routing once test volume and measurement maturity justify it.
Baseline Setup Before the First AI-Led Rewrite
Skipping baseline setup is one of the most expensive mistakes in this category. If you cannot describe current behavior by source, device, and page variant, post-launch improvements become impossible to attribute with confidence.
At minimum, collect a 30- to 60-day control window with traffic source labels, first-screen engagement signals, CTA interaction rates, form progression data, and downstream qualification outcomes. This baseline does not need to be elaborate, but it must be consistent.
Before editing starts, align on one primary objective for the page family. Examples include more qualified demo requests, lower unqualified form volume, or stronger progression from visit to booked call. A clear objective prevents the team from overreacting to surface metrics that do not reflect business quality.
Once baseline data is in place, lock a stable control version. Every AI-assisted update should compare against that control with defined evaluation windows and guardrail metrics.
Section-Level Editing Beats Full-Page Regeneration
Full-page regeneration looks efficient but often creates hidden regressions. Multiple sections change at once, which makes performance movement hard to interpret and harder to trust. Section-level editing is usually slower per draft, but faster for learning.
A practical approach is to map each section to one decision job: relevance, mechanism, proof, objection handling, or action. Then edit only the job linked to the active bottleneck. This keeps each release focused and keeps analytics interpretable.
Teams using this approach also build stronger pattern memory. Over time, they understand which types of edits improve specific outcomes and which edits repeatedly fail. That cumulative knowledge becomes a durable advantage over teams that constantly restart from fresh full-page drafts.
Prompt Design That Produces Usable Output
Prompt quality is not about being clever. It is about reducing ambiguity so output lands closer to publish-ready. Weak prompts ask for "better copy." Strong prompts define audience context, section purpose, tone constraints, and prohibited claim behavior.
A reliable prompt packet includes the following elements. Together, they improve consistency across contributors and reduce avoidable rewrite cycles.
- buyer segment and intent stage
- section role in the decision sequence
- non-negotiable promise boundaries
- approved proof elements available for use
- desired output count and length range
- explicit disallow list for risky phrasing
After draft generation, use a second prompt for critique, not creation. The critique pass should inspect clarity, specificity, credibility, and CTA alignment. Separating these roles reduces the chance that polished but weak language survives to release.
Message Architecture: Keep the Backbone Stable
AI is useful for expression changes, but core architecture should remain stable unless testing shows clear improvement. Most winning pages preserve a consistent narrative spine: immediate audience fit, practical mechanism explanation, confidence support, and a single clear next step.
When architecture drifts, users must reconstruct meaning on their own. That increases cognitive load and weakens decision momentum. Even strong copy can underperform if sequence logic is broken.
If your team needs a reusable blueprint for section sequencing and hierarchy decisions, this landing page structure guide is useful to align architecture before running rapid variation cycles. It is especially helpful when multiple contributors are editing the same page family.
Stability does not mean rigidity. You can still adjust section depth, proof placement, and CTA language by source intent. The key is preserving the decision order so tests compare like with like.
Trust Safety: The Most Overlooked AI Risk
AI-generated writing can sound convincing even when claims are weak or unsupported. That is dangerous on conversion pages where trust signals directly affect action quality. Teams should treat trust safety as an explicit release checkpoint.
Each major claim should have nearby validation, whether that means a transparent process statement, a specific capability boundary, or a concrete proof element already approved by the business. If supporting context is missing, downgrade the claim before publish.
Trust consistency matters across versions as much as within a single page. When different variants make different promises, downstream teams absorb the confusion through lower-quality leads and higher follow-up friction. A claim registry can prevent this drift by listing approved promise language and required evidence anchors.
Personalization Without Overreach
Personalization works when it improves relevance quickly. It fails when it feels intrusive or overly complex. AI makes personalization easier to produce, but good personalization still requires restraint.
The highest-return personalization layer is usually intent-level adaptation: source-aware headline framing, role-specific value emphasis, and objection blocks matched to campaign context. These changes often improve continuity without adding operational risk.
Avoid personalization that depends on fragile assumptions. If the system guesses incorrectly, confidence drops fast and conversion quality suffers. Safe personalization should always degrade gracefully to a credible default experience.
Governance also matters here. Teams should define approved personalization dimensions, prohibited dimensions, and review ownership. This policy keeps experimentation productive while reducing legal and reputational exposure.
CTA and Form Systems for AI-Edited Pages
AI can generate many call-to-action variants, but only a few will match readiness level and message context. The goal is not more CTAs. The goal is one dominant next step that feels obvious at that stage of consideration.
A practical CTA model uses stage-matched intent. This keeps language and commitment level aligned with visitor readiness.
- exploratory visitors: low-commitment progression
- evaluating visitors: validation-oriented progression
- decision-ready visitors: commitment-oriented progression
Form strategy should follow the same principle. Every required field should influence routing or follow-up quality. If a field does not change what happens next, it likely belongs later in the journey.
Post-submit continuity is part of conversion quality. Confirmation messaging should reinforce next steps, set response expectations, and maintain the same promise language used before submission.
Mobile and Performance as Hard Release Gates
Many teams still treat mobile cleanup as a secondary task, but mobile behavior often determines whether high-intent visitors reach the form at all. AI-generated sections can introduce layout shifts, readability issues, or interaction friction that desktop reviews miss.
Minimum mobile QA should include first-screen comprehension, tap target safety, visual hierarchy consistency, keyboard-friendly form interaction, and stable render performance on typical network conditions. Any failure in these checks should block release.
For teams refining mobile interaction and device-first messaging depth, this mobile app landing page conversion guide can support implementation details without breaking your core narrative flow. Apply those mobile checks as mandatory pass conditions before launch.
Performance budgets are equally important. Define threshold targets for time-to-meaningful-content, CTA interaction readiness, and form response latency. AI speed in drafting is irrelevant if published pages slow down user decisions.
Experiment Design: Higher Signal, Less Noise
Rapid content generation can tempt teams into high-variant chaos. That typically creates inconclusive data, false positives, and wasted cycles. Controlled experiment design protects learning quality.
Each release cycle should include one major hypothesis tied to one observable user behavior change. Supporting edits may be necessary, but they should remain minor and documented. This discipline keeps interpretation reliable.
Before launch, document four items: hypothesis, primary metric, guardrail metric, and decision threshold. This simple habit reduces post-test rationalization and keeps teams aligned when results are mixed.
When traffic is limited, prioritize fewer, stronger variants over broad multivariate spreads. AI should accelerate targeted experiments, not increase experiment entropy.
Best practices from CXL emphasize that controlled A/B testing with clear hypotheses and limited variables produces more reliable insights than broad multivariate experimentation. Keeping test scope focused helps teams attribute performance changes accurately and build reusable learning over time.
Measurement Hierarchy for Commercial Outcomes
Page-level conversion rate is important but incomplete. Teams need a layered measurement model to avoid optimizing for low-quality volume.
A practical hierarchy can be applied to every release review. Using the same sequence each cycle makes trend interpretation far easier.
- Attention and progression metrics: did users engage with the sections that drive decisions?
- Action metrics: did users complete the intended conversion event?
- Qualification metrics: did those conversions meet downstream fit criteria?
- Business metrics: did qualified actions progress to opportunity and revenue impact?
Decision reviews should always pair a top-layer metric with at least one downstream guardrail. Without this pairing, programs often celebrate gains that increase operational burden while reducing pipeline quality.
When teams need a stronger behavior-first lens for interpreting page outcomes, these user behavior optimization principles help connect interaction signals to practical next edits. This reinforces decision quality when surface metrics move in conflicting directions.
Governance Model: Who Owns What
AI-assisted workflows fail when ownership is vague. If everyone can publish and no one owns claim safety or measurement integrity, regression becomes inevitable.
A clear operating model usually includes four roles. Assigning these roles in writing prevents ownership drift during rapid release cycles.
- strategy owner: defines target segment, offer logic, and test priorities
- editorial owner: validates clarity, brand fidelity, and promise consistency
- analytics owner: defines metric framework and reads experiment outcomes
- release owner: enforces QA gates and publication standards
Small teams can combine roles, but responsibilities should still be explicit. Governance is less about bureaucracy and more about reducing avoidable mistakes during high-speed iteration.
A 30-Day Implementation Blueprint
Week 1: Foundation and Baseline
Audit active landing pages by traffic source, conversion path, and downstream quality indicators. Identify the top two bottlenecks where improvement would materially change outcomes. Finalize your control version and align on objective metrics.
Create or refresh the core page template with stable section order and approved claim language. This template becomes the reference frame for all upcoming AI-assisted edits.
Week 2: Controlled Drafting and First Release
Build prompt packets for one high-priority section, then generate a small set of alternatives. Run editorial and trust review before moving any version to staging.
Complete mobile, performance, and form QA checks. Publish one controlled variant against the control version with an explicit observation window.
Week 3: Measure, Refine, and Expand Carefully
Review results with both conversion and qualification signals. If outcomes are positive and stable, adapt the winning logic to one additional section or segment. If outcomes are mixed, isolate the likely driver before launching another major edit.
Update prompt and QA libraries with what worked and what failed. Documenting these lessons prevents repeated low-quality tests.
Week 4: Operationalize
Formalize review cadence, ownership, and release checklist usage. Establish a monthly decision review focused on bottlenecks, not vanity metrics.
For teams scaling AI-assisted page creation across multiple campaigns, this AI landing page creation playbook helps keep expansion aligned with quality controls and conversion intent. Use it as a reference when turning single-page wins into repeatable production standards.
90-Day Scale Plan for Mature Teams
The first month should establish control. The next two months should establish repeatability. At 90 days, the objective is not just better pages, but a better operating system for page decisions.
Month two should concentrate on structured variant expansion by source and intent. Keep architecture stable while tailoring relevance and proof depth where data shows clear segment differences.
Month three should focus on institutional memory: tested patterns, failed patterns, approved claims, and reusable prompt packets by section type. Teams that maintain this knowledge base reduce ramp time for new contributors and improve execution quality over time.
At this stage, consider whether dynamic routing or deeper personalization is justified by traffic volume and signal quality. Add complexity only when the team can measure it credibly.
Common Failure Modes and Practical Fixes
Failure Mode 1: "Everything improved" but lead quality dropped
This usually indicates top-of-funnel metrics were optimized without qualification guardrails. Fix the reporting model first, then refine CTA language and form logic to better match readiness stage.
Failure Mode 2: Copy sounds polished but message clarity declined
Polished phrasing can hide weak specificity. Reduce abstraction, make outcomes concrete, and ensure mechanism language explains how value is delivered in practical terms.
Failure Mode 3: Too many variants, no confident winner
Testing capacity exceeded traffic reality. Narrow the variant set, extend observation windows, and require one major hypothesis per cycle.
Failure Mode 4: Sales and marketing disagree on page quality
Page language drifted away from real buyer conversations. Build a feedback loop where front-line objections inform FAQ, proof, and CTA refinements.
Failure Mode 5: Fast publishing introduced trust risk
Review gates were bypassed under schedule pressure. Reinstate claim checks, approval ownership, and release blocking criteria before the next campaign cycle.
Scenario Playbooks
Startup launch motion
Early-stage teams usually need fast message learning and credible first conversion signals. Use a single stable template, run one section-level test per week, and prioritize clarity over design novelty. Keep forms short, follow-up expectations explicit, and analytics simple enough to maintain consistently.
SaaS demand capture motion
SaaS teams often struggle with traffic-source mismatch. Map each high-volume source to an intent stage, then adapt first-screen framing and proof density accordingly. Keep core positioning fixed across variants so comparison remains meaningful.
Agency or multi-client motion
Agency teams require stronger process standardization because contributor count is high. Build shared prompt packets, shared QA checklists, and shared release roles across accounts. This reduces quality variance and improves handoff efficiency.
Enterprise compliance-sensitive motion
Enterprise programs should prioritize governance-first tool selection. Approval routing, component locking, and auditability matter as much as drafting speed. AI can still accelerate production, but release authority must stay tightly controlled.
FAQ: AI-Assisted Landing Page Updates
1. How many AI-generated variants should we test at once?
For most teams, two to four meaningful variants per cycle is enough. Beyond that range, signal quality often drops unless traffic is very high and measurement rigor is strong.
2. Should we rewrite full pages with AI or only sections?
Section-level updates are usually safer and more informative. Full rewrites can be useful occasionally, but they make attribution harder because too many variables change at once.
3. What is the first section to optimize for faster wins?
First-screen relevance and CTA clarity typically produce the fastest measurable impact. If users do not immediately understand fit and next step, deeper sections rarely compensate.
4. How do we prevent AI output from sounding generic?
Give the model richer constraints and clearer context. Include segment details, desired mechanism emphasis, and explicit language boundaries, then run a critique pass before any publish decision.
5. How often should we update our prompt library?
Refresh it after each meaningful experiment cycle. Add successful patterns, remove weak patterns, and include notes on where each prompt performs best.
6. Can small teams run this process without dedicated specialists?
Yes, if ownership is still explicit. One person can hold multiple roles, but responsibility for strategy, review, analytics, and release standards must remain clear.
7. What makes personalization safe versus risky?
Safe personalization improves relevance using stable, intent-level context. Risky personalization depends on assumptions that may be wrong or intrusive and can weaken trust quickly.
8. How long should we wait before declaring a test winner?
Use a predefined observation window tied to traffic volume and conversion cadence. Ending tests early based on small spikes is one of the fastest ways to create false confidence.
9. Which metrics should always appear in decision reviews?
Include one behavior metric, one action metric, and at least one downstream quality guardrail. This mix prevents local page improvements from hiding broader funnel regressions.
10. When should we add advanced routing or dynamic delivery?
Add those layers only when baseline instrumentation is reliable and traffic volume can support controlled learning. Advanced features create value when they improve signal quality, not when they add operational noise.
Final Takeaway
AI-assisted landing page work is most valuable when it improves how your team makes decisions, not just how quickly it writes. The winning system is simple: stable architecture, focused hypotheses, strict QA gates, and clear ownership at release time.
If you keep those fundamentals in place, AI becomes a force multiplier for conversion quality instead of a source of unpredictable drift. That is the operating advantage that compounds over time.
Related Blog Posts
- Free AI landing page generator
- AI Landing Page Generator: A Practical 2026 Guide for Faster Launch and Better Conversion
- AI-Driven Landing Page Workflows in 2026: How Teams Move Faster Without Losing Conversion Quality
- Building AI Applications in 2026: A Practical Guide to Product Utility and Conversion Readiness

